
Using Spark Streaming, Apache Kafka, and Object Storage on IBM Bluemix

Some of the services provided by IBM Bluemix enable you to significantly speed up the implementation of the IoT use cases. With Bluemix, you are not required to deploy and configure Hadoop, Apache Kafka, or other big data tools. It allows you to launch service instances in a few clicks.
In this tutorial, we explain how to integrate and use the most popular open-source tools for stream processing. We explore IBM Message Hub (for collecting streams), the Apache Spark service (for processing events), and IBM Object Storage (for storing results).
Sample scenario
Below is the scheme of a stream processing flow that we will implement in this post.
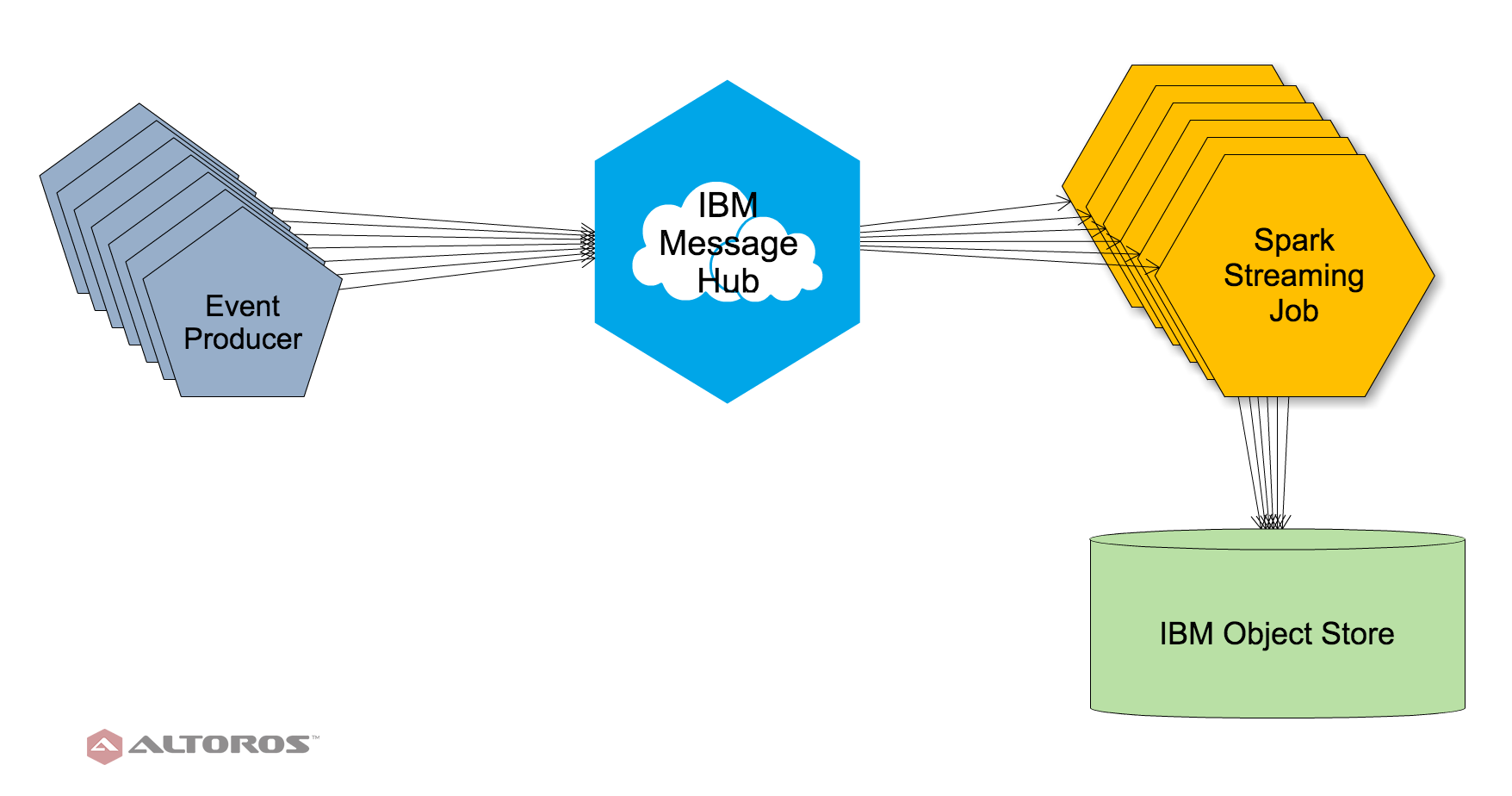 A sample stream processing workflow
A sample stream processing workflowEvent Producer generates sample messages, which then go to Message Hub. Spark jobs pick them up from Message Hub, process, and store in the Object Storage files.
Here is the code of our message producer that sends real-time data to Bluemix Message Hub.
IBM Message Hub for Bluemix supports two message queuing systems: Apache Kafka and IBM MQ Light. In our sample flow, we use Apache Kafka as a tool for big data stream processing.
For configuring a connection to IBM Message Hub, check out this sample and documentation.
Apache Spark on Bluemix
To enable support for Spark Streaming, you need to include this library that contains the implementation of Spark Streaming into Spark dependencies.
Now, you can use StreamingContext with the following code:
val ssc = new StreamingContext(sc, Seconds(2))
 Developing a Spark job
Developing a Spark jobFor debugging our Spark job, we used Jupyter, a tool provided by the Bluemix Spark service for interactive job development. First, we develop some functionality in Jupyter and then copy it to our job that will further be submitted to the Apache Spark service.
Debugging a Spark job
Integrating Spark with Message Hub
To integrate Apache Spark with Message Hub:
- Include this additional IBM-specific library into your Spark job configuration.
- In your Spark job, provide the following configuration:
val kafkaProps = new MessageHubConfig
kafkaProps.setConfig("bootstrap.servers", "kafka01-prod01.messagehub.services.us-south.bluemix.net:9093")
kafkaProps.setConfig("kafka.user.name", "XXXXXXXXXXXXXXXXXX")
kafkaProps.setConfig("kafka.user.password", "**************")
kafkaProps.setConfig("kafka.topic", "mytopic")
kafkaProps.setConfig("api_key", "*******************************")
kafkaProps.setConfig("kafka_rest_url", "https://kafka-rest-prod01.messagehub.services.us-south.bluemix.net:443")
kafkaProps.createConfiguration()
val sc = new SparkContext()
val ssc = new StreamingContext(sc, Seconds(2))You can find all the credentials needed for running Kafka in the Credentials section of the Message Hub service in the Bluemix console.
Now, you should be able to connect to Kafka and receive new events in real time.
val stream = ssc.createKafkaStream[String, String, StringDeserializer, StringDeserializer](
kafkaProps,
List(kafkaProps.getConfig("kafka.topic"))
)
Integrating Spark Streaming with Bluemix Object Storage
You might want to check out this post that gives you details on how to integrate the Spark service with Object Storage. To connect to Object Storage, you need to provide the following configuration in your Spark job:
val pfx = "fs.swift.service." + name val conf = sc.getConf conf.set(pfx + ".auth.url", "https://identity.open.softlayer.com") conf.set(pfx + ".tenant", "sf56-d54664602866ee-20565106c03e") conf.set(pfx + ".username", "Admin_58ad00f71fbcbebe819624b6d70df9ec6a494887") conf.set(pfx + ".auth.endpoint.prefix", "endpoints") conf.set(pfx + ".password", "************") conf.set(pfx + ".apikey", "************") conf.set(pfx + ".region", "dallas") conf.set(pfx + ".hostname", "notebooks")
In this configuration, name is the job name. You can find the corresponding configuration settings in the Credentials section of your Object Storage service. Also, keep in mind that you need to pass the user_id property from the Credentials section to the username option.
Generating and processing events
The event producer code (we copied it with small modifications from IBM Message Hub samples):
public void run() {
logger.log(Level.INFO, ProducerRunnable.class.toString() + " is starting.");
while (!closing) {
String fieldName = "records";
// Push a message into the list to be sent.
MessageList list = new MessageList();
list.push("This is a test message" + producedMessages);
try {
// Create a producer record which will be sent
// to the Message Hub service, providing the topic
// name, field name and message. The field name and
// message are converted to UTF-8.
ProducerRecord<byte[], byte[]> record = new ProducerRecord<byte[], byte[]>(
topic,
fieldName.getBytes("UTF-8"),
list.toString().getBytes("UTF-8"));
// Synchronously wait for a response from Message Hub / Kafka.
RecordMetadata m = kafkaProducer.send(record).get();
producedMessages++;
logger.log(Level.INFO, "Message produced, offset: " + m.offset());
Thread.sleep(1000);
} catch (final Exception e) {
e.printStackTrace();
shutdown();
// Consumer will hang forever, so exit program.
System.exit(-1);
}
}
logger.log(Level.INFO, ProducerRunnable.class.toString() + " is shutting down.");
}The code for the stream processing job:
object StreamProcessor {
def main(args: Array[String]) {
val configureKafka: MessageHubConfig = configureKafka
val sc = new SparkContext()
configureObjectStore(sc, "test3")
val ssc = new StreamingContext(sc, Seconds(2))
val stream = ssc.createKafkaStream[String, String,
StringDeserializer, StringDeserializer](
configureKafka,
List(configureKafka.getConfig("kafka.topic"))
)
stream.saveAsTextFiles("swift://notebook.test3/result.csv")
ssc.start()
ssc.awaitTermination()
}
def kafkaProps: MessageHubConfig = {
val kafkaProps = new MessageHubConfig
kafkaProps.setConfig("bootstrap.servers", "kafka01-prod01.messagehub.services.us-south.bluemix.net:9093")
kafkaProps.setConfig("kafka.user.name", "*******************")
kafkaProps.setConfig("kafka.user.password", "********************")
kafkaProps.setConfig("kafka.topic", "mytopic")
kafkaProps.setConfig("api_key", "***********************")
kafkaProps.setConfig("kafka_rest_url", "https://kafka-rest-prod01.messagehub.services.us-south.bluemix.net:443")
kafkaProps.createConfiguration()
kafkaProps
}
def configureObjectStore(sc: SparkContext, name: String): Unit = {
val pfx = "fs.swift.service." + name
val conf = sc.getConf
conf.set(pfx + ".auth.url", "https://identity.open.softlayer.com")
conf.set(pfx + ".tenant", "sf56-d54664602866ee-20565106c03e")
conf.set(pfx + ".username", "Admin_58ad00f71fbcbebe819624b6d70df9ec6a494887")
conf.set(pfx + ".auth.endpoint.prefix", "endpoints")
conf.set(pfx + ".password", "****************")
conf.set(pfx + ".apikey", "****************")
conf.set(pfx + ".region", "dallas")
conf.set(pfx + ".hostname", "notebooks")
}
}
Conclusion
During the development, we found out that Zookeeper—the regular tool for managing Kafka—was replaced by IBM with a special REST API, which makes the Message Hub API incompatible with many software created for typical Kafka deployments.
Also, the authentication and authorization process to access Message Hub is not trivial: it includes multiple steps and works with files somewhat unsuitable for a cloud environment.
We also found out that the integration of the Spark service with other Bluemix services is quite challenging. For integrating Spark with Message Hub, you need an additional dependency from IBM.
In general, usage of IBM Bluemix allows you to save about one man-month of work, since we avoid installation, configuration, and integration of multiple big data tools. However, development could be even more simplified by providing a mechanism for easier integration of different Bluemix services with each other. Let’s hope that IBM will implement it some day.
Further reading
- Processing Data on IBM Bluemix: Streaming Analytics, Apache Spark, and BigInsights
- An IoT Platform on Bluemix: Experimenting with IBM Watson and Gobot





