The Magic Behind Google Translate: Sequence-to-Sequence Models and TensorFlow
A technology underlying Google Translate
What is the magic that makes Google products so powerful? At TensorFlow Dev Summit 2017, the attendees learnt about the sequence-to-sequence models that back up language-processing apps like Google Translate. Eugene Brevdo of Google Brain discussed the creation of flexible and high-performance sequence-to-sequence models. In his session, Eugene explored:
- reading and batching sequence data
- the RNN API
- fully dynamic calculation
- fused RNN cells for optimizations
- dynamic decoding

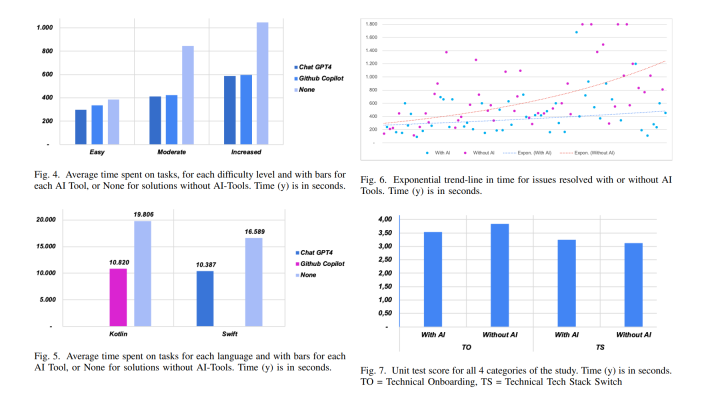
He exemplified Google Translate, which is now backed up by a neural network, specifically by a sequence-to-sequence model. (Previously, Xiaobing Liu, another member of the Google Brain team, talked about automating conventional phrase-based machine translation in this product.)
A sequence-to-sequence model is basically two recurrent neural networks: an encoder and a decoder. The encoder reads in one word or a word piece at a time, creating some intermediate representation. Then, the decoder receives a start token that triggers decoding—also a single word or word piece at time—in the target language. On admitting a token, the decoder feeds it back into the next time step, so that the token and the previous state are used to figure out what to emit next.

What may look quite trivial is more sophisticated in reality.
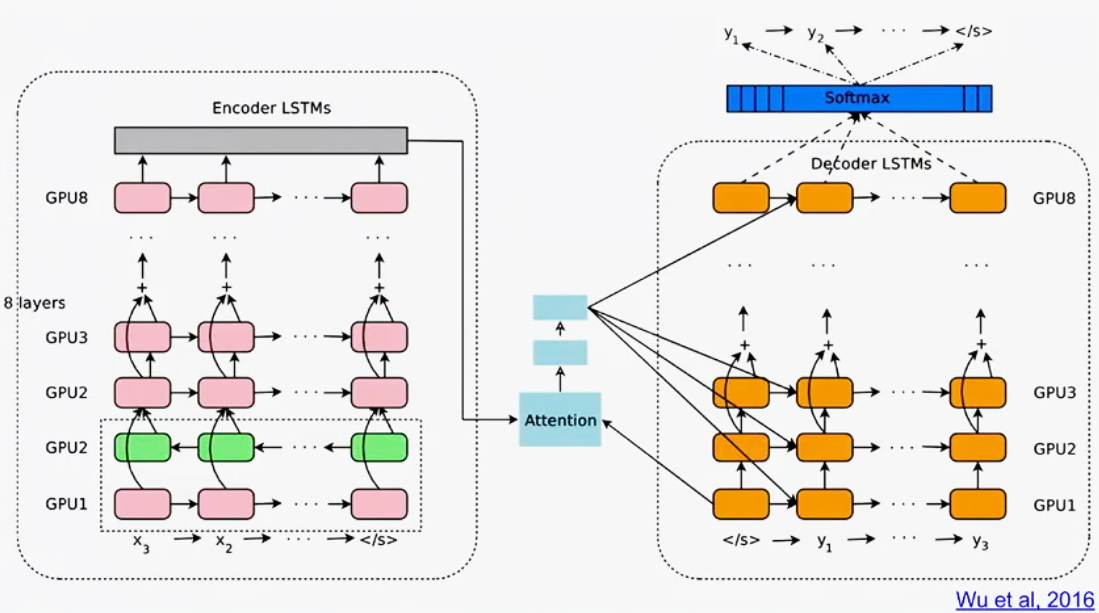
Reading and batching sequence data
When scaling up a training model, it’s important to be able to feed in large volumes of mini batches of variable-length data. For this purpose, the Google Brain team employs the SequenceExample protocol, which is language- and architecture-agnostic data storage format. (Furthermore, there is a collection of such protocol buffers for serializing structured data.)
The SequenceExample format is designed specifically to store variable-length sequences. The perks of this format are the following:
- It provides efficient storage of multiple sequences per example.
- It supports a variable number of features per time step.
- There is a parser that reads in a serialized proto string and emits tensors and/or sparse tensors in accordance with the configuration.
- The SequenceExample protocol is planned to be a “first-class citizen” within TensorFlow Serving. It means that users will be able to generate data both at training and serving phases.
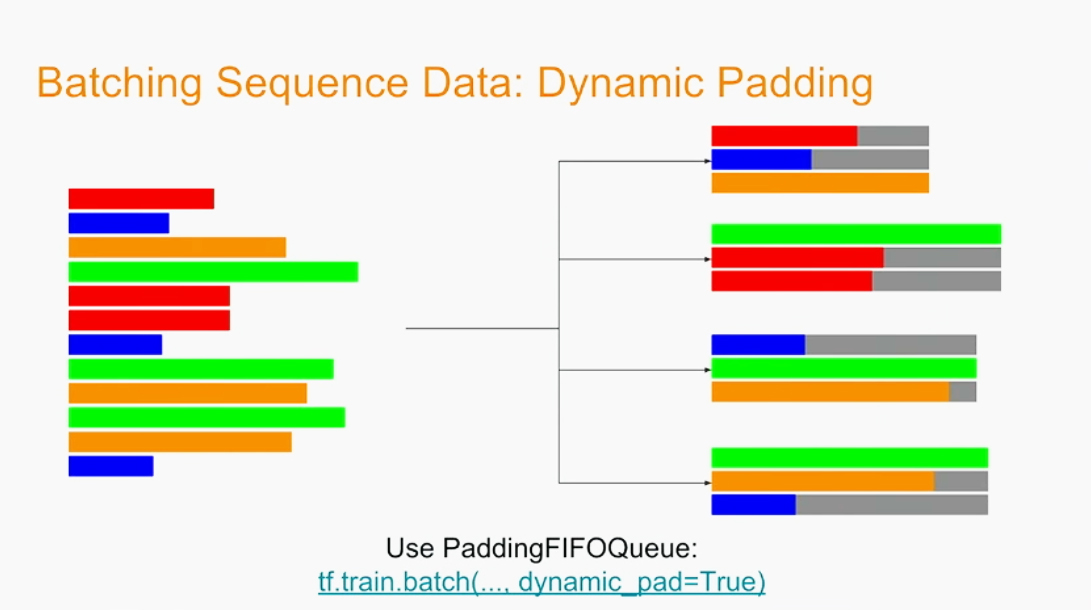
Once you can read in a sequence at a time, you have to batch it. Padding can be done manually, which is naturally time-consuming. The second option is to allow the batching mechanism to perform the padding. However, you’ll will inevitably come to a point, where the padding queue adjusts all the sequences to the longest one detected. Still, when scaling up the training model, batch sizes are constantly growing, so you’ll be back to wasting space and computation time. What is the right thing to do, then?
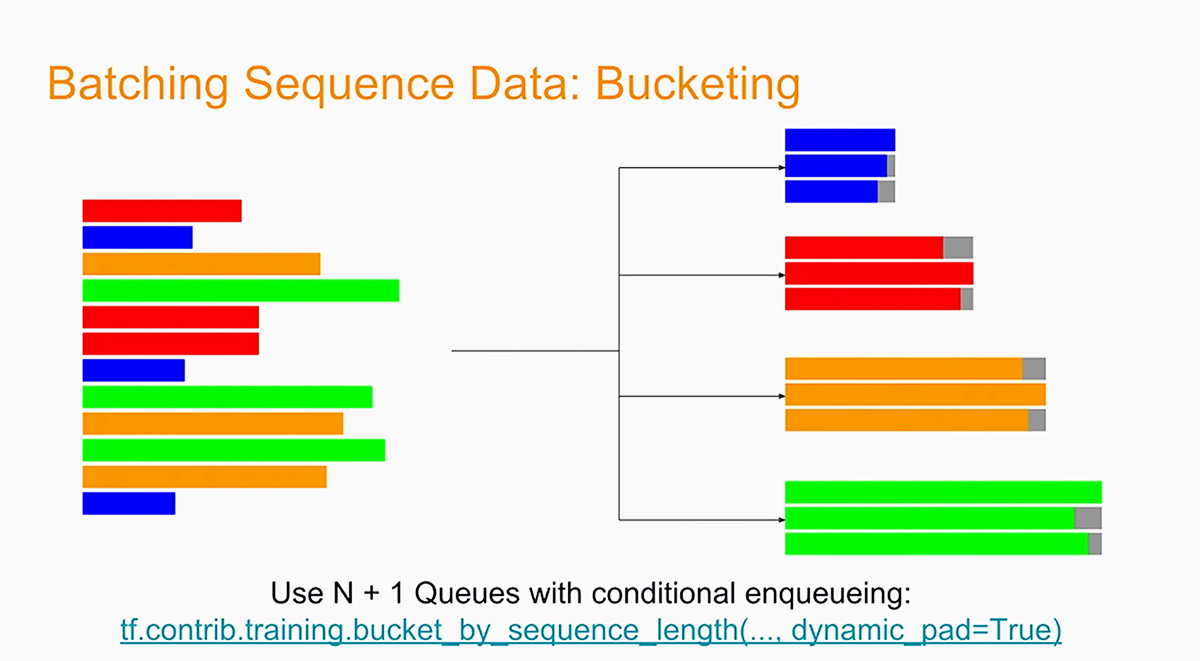
One has to create a number of different queues—buckets—running in parallel. When you pass a variable-length sequence into this mechanism, it will put it into one of a number of queues. Each queue will only contain sequences of the same length, so there is little padding to do. The function employed behind the process is Bucket-by-Sequence Length—tf.contrib.training.bucket_by_sequence_length(..., dynamic_pad=True).
There is also a State Saver used to implement Truncated Backpropagation Through Time.

“What it means is that you pick a fixed number of time steps you unroll for, and any sequence, which is longer than this number of time steps, gets split up into multiple segments. When you finish your mini batch, any sequences or segments, which are not the completed sequence, the state is saved for you. Some bookkeeping is done in the background, and at the next training iteration, the state is loaded. So, you continue sequence processing with that saved state.” —Eugene Brevdo, Google Brain
The function behind is tf.contrib.training.batch_sequences_with_states(...).


Fully dynamic calculation
Eugene highlighted two TensorFlow-based tools—tf.while_loop and tf.TensorArray—that enable users to easily create memory-efficient custom loops, handling sequences of unknown length.
tf.while_loop helps to create dynamic loops and supports backpropagation. tf.TensorArray is employed to read and write “slices” of tensors, supporting gradient backpropagation, as well.

Later in his talk, Eugene focused on dynamic decoding and fused RNN cells to drive optimization.
Want details? Watch the video!
Further reading
- Enabling Multilingual Neural Machine Translation with TensorFlow
- Natural Language Processing and TensorFlow Implementation Across Industries
- How TensorFlow Can Help to Perform Natural Language Processing Tasks
- Analyzing Text and Generating Content with Neural Networks and TensorFlow
About the expert
Eugene Brevdo is a software engineer on Google’s Applied Machine Intelligence team. He primarily works on TensorFlow infrastructure, recurrent neural networks, and sequence-to-sequence models. Eugene’s research interests include variational inference and reinforcement learning, with applications in speech recognition and synthesis, and biomedical time series. You can check out his GitHub profile.