
Processing Data on IBM Bluemix: Streaming Analytics, Apache Spark, and BigInsights

Essentially, the Internet of Things is about collecting and exchanging data, which then can be used in many different ways. Equipment fault monitoring, predictive maintenance, or real-time diagnostics are only a few of the possible scenarios. Dealing with all this information, however, creates certain challenges for the field of the IoT, and stream processing of huge amounts of data is among them.
In this article, we compare IBM Bluemix services for real-time processing of data streams—IBM InfoSphere Streams, a managed Apache Spark service, and IBM BigInsights for Apache Hadoop.
Streaming Analytics
IBM InfoSphere Streams is a platform for stream processing. It provides a wide set of connectors to different data stream sources and has good support of standard stream processing algorithms and approaches. For programming with this technology, a special Eclipse-based IDE—IBM Streams Studio—and a set of domain-specific languages are included. The main language used for processing data streams is Streams Processing Language (SPL).
Below is an example of event processing using IBM Streams SPL:
composite HelloWorld {
graph
stream<rstring message> Hi = Beacon() {
param iterations : 1u;
output Hi : message = "Hello, world!";
}
() as Sink = Custom(Hi) {
logic onTuple Hi : printStringLn(message);
}
} IBM Streams Studio
IBM Streams StudioThe advantages of IBM Streams:
- Large set of connectors
- Good support of standard algorithms for text processing and pattern matching
- High scalability and performance
The disadvantages:
- It requires learning new programing languages to get started.
- The installation of IBM Streams Studio is difficult. Also, it does not support all desktop platforms.
- It is not possible to develop without proprietary IBM Streams Studio.
- You cannot reuse app logic implemented using SPL on other platforms/apps.
Apache Spark on Bluemix
Apache Spark is a fast and general engine for large-scale data processing. On Bluemix, it is available as a part of two services: Apache Spark and BigInsights for Apache Hadoop.
The Spark service on Bluemix is represented by a separate Spark master and worker nodes, and it also provides an interactive code editor Jupyter. As the default file storage, the service uses Swift-based IBM Bluemix Object Storage. However, the integration is not good enough at the current moment: additional code is required for configuring and applying parameters in Spark. Now, the Spark service supports the Scala, R, and Python languages. For stream processing, you can work with Spark Streaming.
Jupyter editor for the Bluemix Spark service
The advantages of Apache Spark on Bluemix:
- Good documentation
- Large community
- Support for existing Python, R, and Scala libraries
- No need to learn a new language
- High performance and scalability
- Reliability
The disadvantages:
- Integration with other Bluemix services, such as Object Storage, IBM BigInsights (Hadoop), and IBM Message Hub, is not perfect.
- You need a lot of time to get started. At the moment, it is quite challenging to integrate different data services with Spark: there are a number of difficult actions that are not well documented. For developing a real stream processing flow, it will require even more time to integrate all stream providers and data stores.
- It is problematic to program. Internal integrations with other services, including third-party libraries, are quite complicated to develop and debug. You have to use the Jupyter editor for debugging and another IDE for development, which require some kind of constant code synchronization.
IBM BigInsights for Apache Hadoop
IBM BigInsights enables you to create a Hadoop cluster with one click. It contains a pre-installed Apache Spark service on all cluster nodes. Unfortunately, BigInsights does not provide any web-based interface for uploading and managing Spark jobs. You can submit jobs to this cluster only via the command line. Debugging of these jobs also is not trivial. BigInsights offers the Ambari web console for monitoring cluster health.
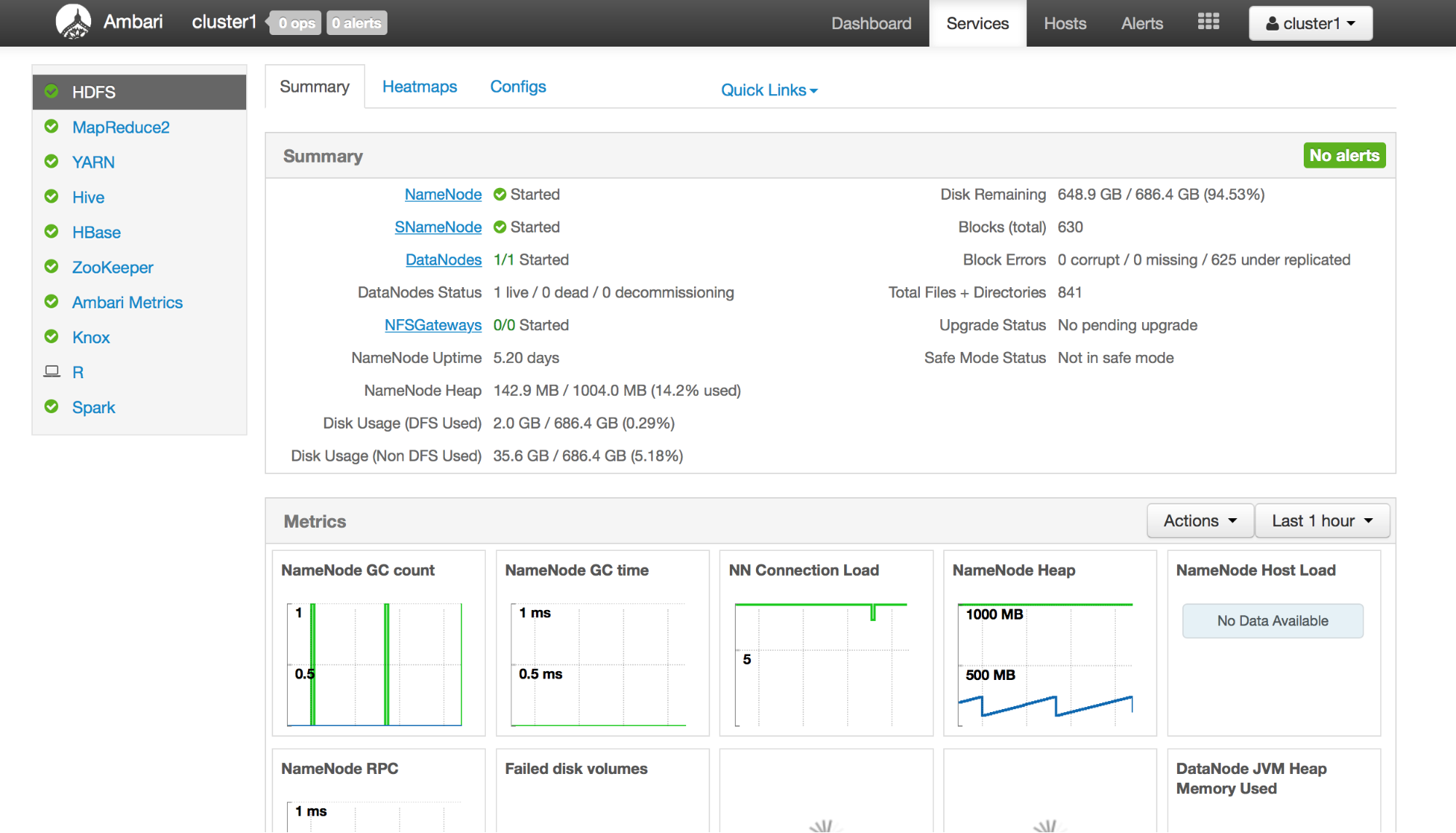 Ambari cluster manager for the BigInsights service
Ambari cluster manager for the BigInsights serviceThe advantages of IBM BigInsights for Apache Hadoop:
- You can quickly create a Hadoop cluster with good integration between all components.
- You are able to store streams to a Hadoop-based data lake as well as to process it.
The disadvantages include:
- Integration with other Bluemix services is weak.
- There is no web console for creating, managing, and executing stream processing jobs and interactive programming of stream processing workflows.
Conclusions
As already said, Bluemix has three services for programmable processing of data streams: IBM Streams, Apache Spark, and IBM BigInsights for Hadoop. Their comparison is summarized in the table below.
| Criteria | IBM Streams | Apache Spark on Bluemix | IBM BigInsights for Hadoop |
|---|---|---|---|
| Languages | SPL, Java | Scala, R, Python | Scala, R, Python |
| Development tools | IBM Streams Studio | Web-based Jupyter or any desktop IDE | Any desktop IDE |
| Integration with file storage | Difficult | Difficult | Simple (It is possible to use HDFS provided by BigInsights.) |
| Integration with other Bluemix services | Bad | Bad | Bad |
| Reuse of third-party libraries | Difficult | Simple | Simple |
| Time to start for beginners | Long | Long | Long |
| Community | Small | Large | Large |
Among the services, Apache Spark and IBM BigInsights for Hadoop are the most comfortable and easy to work with. IBM Streams is more difficult to use, but it has good support of techniques and algorithms for stream text processing and pattern matching. However, all the three share the same issue—their integration with other Bluemix services could be much better. Solving this problem will certainly make the Bluemix data stream processing solutions more appealing to users.
Further reading
- Bluemix Tutorial: Using IBM Analytics for Apache Spark in Java/Scala Apps
- Using Spark Streaming, Apache Kafka, and Object Storage for Stream Processing on Bluemix



