
Osaka University Cuts Power Consumption by 13% with Kubernetes and AI
Increasing power consumption is a problem
Over the past few years, edge computing, which places computation and data storage closer to the devices where it is being gathered, has become more prevalent due to the widespread adoption of the Internet of Things (IoT). Edge computing using 5G networks may reduce communication time between devices, but management tasks are becoming more and more complex. Additionally, the steady increase of IoT devices and the growing demand for 5G networking has led to a rise in the amount of computing resources necessary to operate such systems.
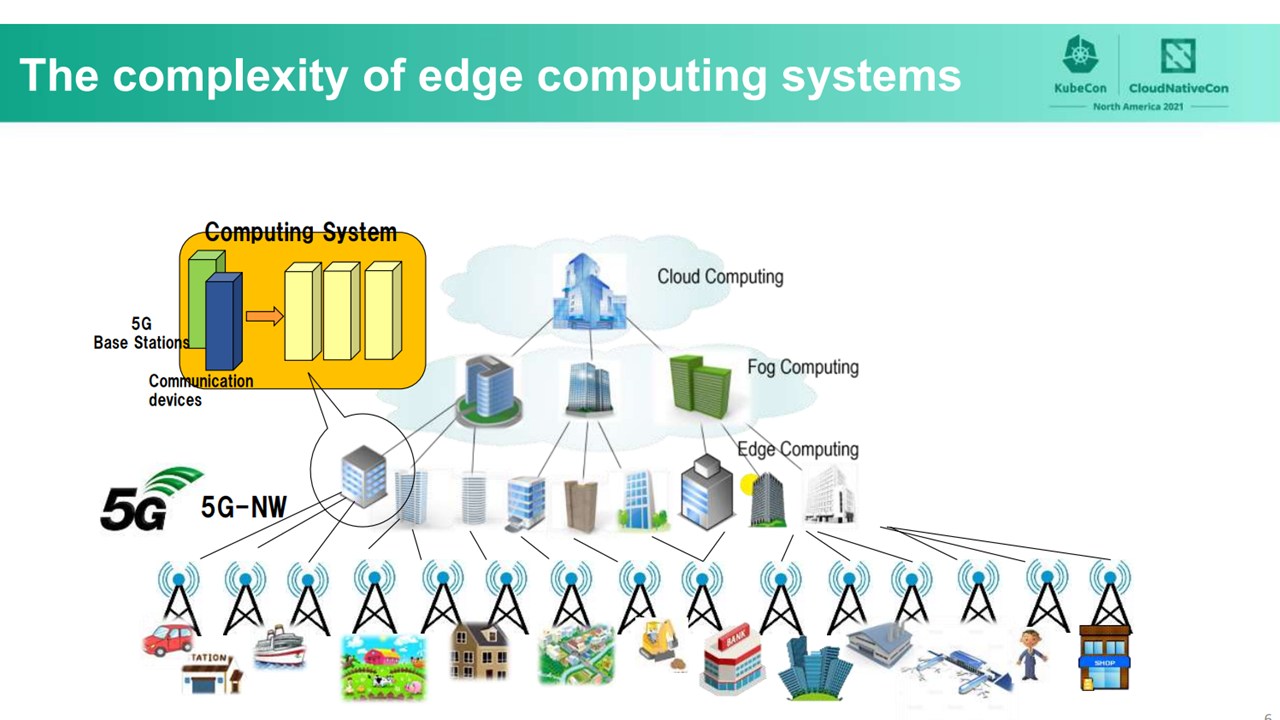 Managing multiple devices (Image credit)
Managing multiple devices (Image credit)The problem with managing complex systems can be resolved with Kubernetes. The open-source container orchestration system enables organizations to simplify the management of large amounts of computing resources. However, even with Kubernetes, the total power consumption due to an increased amount of computing resources remains a key issue.
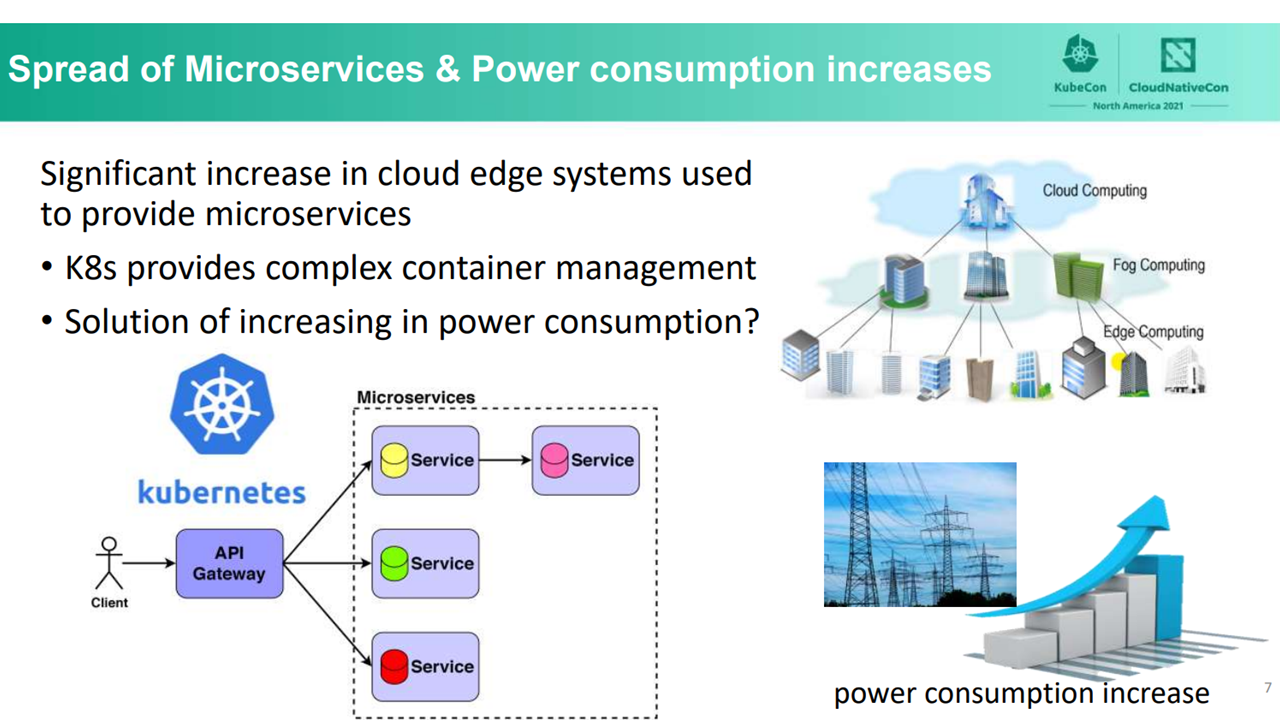 Power consumption becoming an issue (Image credit)
Power consumption becoming an issue (Image credit)During the KubeCon and Cloud Native Conference North America 2021, Ying-Feng Hsu, Assistant Professor at Matsuoka Laboratory in Osaka University, shared how the institution is working on addressing power consumption concerns. Matsuoka Laboratory regularly conduct experiments to reduce power consumption. The lab has access to two data centers in Osaka with around 350 servers each. Ying-Feng demonstrated a proof-of-concept design for low power consumption policies for an open-source Kubernetes implementation.
Developed by Ying-Feng along with fellow researchers Kazuhiro Matsuda and Morito Matsuoka, the proof-of-concept uses a neural network to create a workload allocation optimizer (WAO) and extending it through Kubernetes to achieve power consumption reduction in an edge computing system. The proof-of-concept solution is an extension of the previous experiments at Osaka University, where the researchers utilized deep learning to reduce data center power consumption by up to 70%.

Ying-Feng Hsu
“Kubernetes focuses on high performance container orchestration in large-scale environments. However, Kubernetes does not provide container orchestration from the perspective of power consumption reduction, and there are relatively few discussions in the community on how to operate containers while considering both energy saving and service performance. For example, it would be great if we can consider various application requests, as well as different capacities and performances of computing resources before deploying microservices.” —Ying-Feng Hsu, Osaka University
What is the workload allocation optimizer?
To better understand how WAO can reduce power consumption, the process for task allocation in Kubernetes should be explained first. The default task scheduler—Kube-scheduler—uses a pod as the smallest deployable unit. A pod may consist of a single or multiple containers. When distributing pods to nodes, Kubernetes does not provide advanced network load balancers. According to the researchers at Osaka University, when allocating tasks to candidate pods, even with MetalLB, Kubernetes clusters only provide simple load balancers with equal probability.
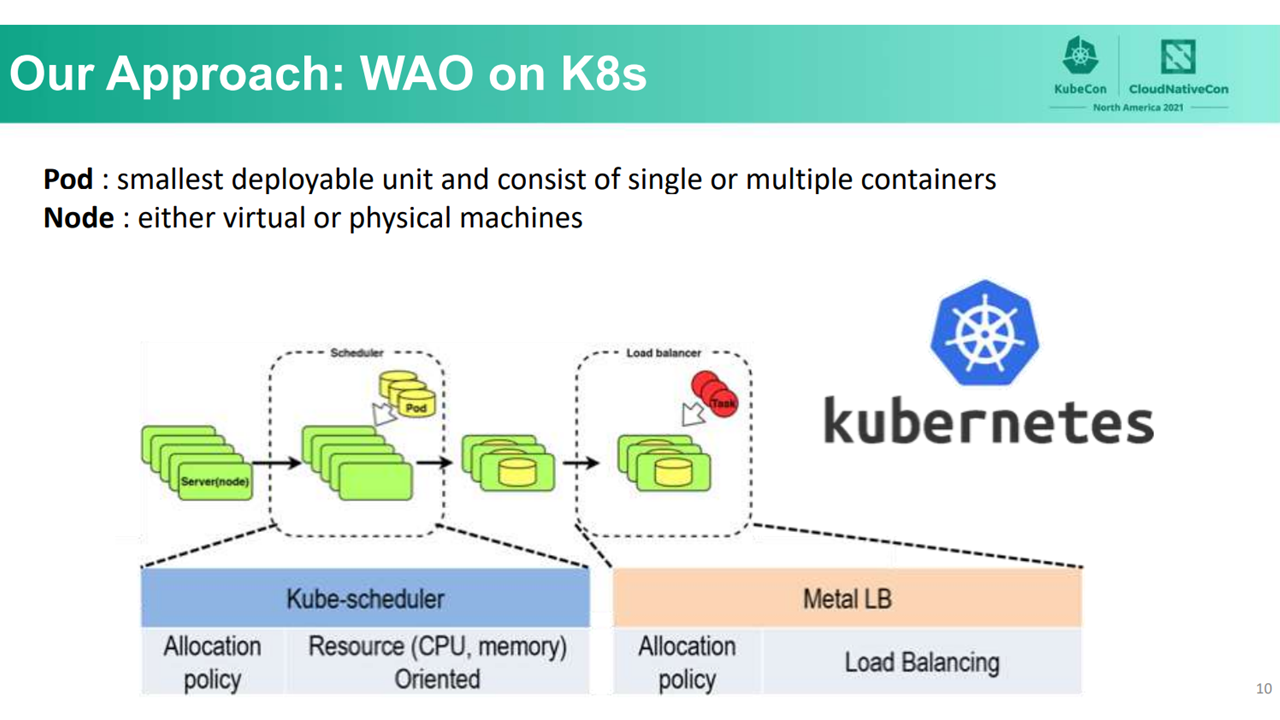 The absence of default power consumption optimization in Kubernetes (Image credit)
The absence of default power consumption optimization in Kubernetes (Image credit)To reduce power consumption in Kubernetes, it is necessary to prioritize the relationship between power consumption and CPU usage when allocating tasks. To achieve this, the team at Osaka University implemented a WAO-based scheduler (WAO-scheduler) to allocate pods and a WAO-based load balancer (WAO-LB) to allocate tasks.
WAO-scheduler is a custom kube-scheduler that ranks nodes using a neural network–based prediction model. A higher rating for a node indicates that it is expected to have a lower increase in power consumption when employing computing resources. The researchers used WAO-LB to define an evaluation formula based on the concept of osmotic pressure and add power consumption (PC) and response time (RT) models using neural networks.
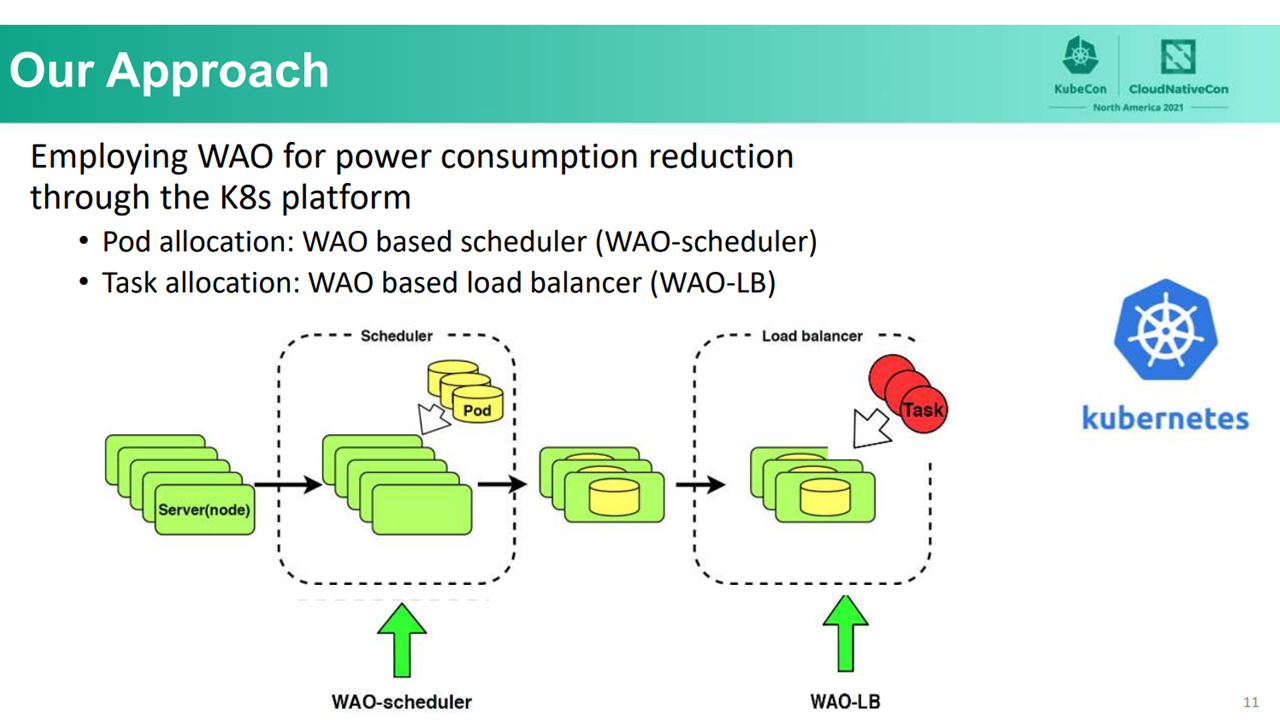 WAO-scheduler and WAO-LB (Image credit)
WAO-scheduler and WAO-LB (Image credit)“The main concept of WAO is to use machine learning to predict server power consumption and perform optimal task allocations. In other words, we created a power consumption model using machine learning. Based on the model, WAO allocates tasks to the server with the least amount of power consumption.” —Ying-Feng Hsu, Osaka University
How is power consumption factored in?
By default, when a pod deployment request is received, kube-scheduler determines to which node each pod in the scheduling queue should be placed based on available resources and constraints. This process includes three primary orderly phases: filtering, scoring, and binding. In the filtering phase, kube-scheduler lists all the available nodes that meet the pod’s resource requirement. Next, in the scoring phase, the available nodes are ranked based on their scores, which are calculated with default priority functions. The node with the highest score is then selected. Finally, in the binding phase, kube-scheduler, via the API server, notifies the selection of the best node in which a pod is formed.
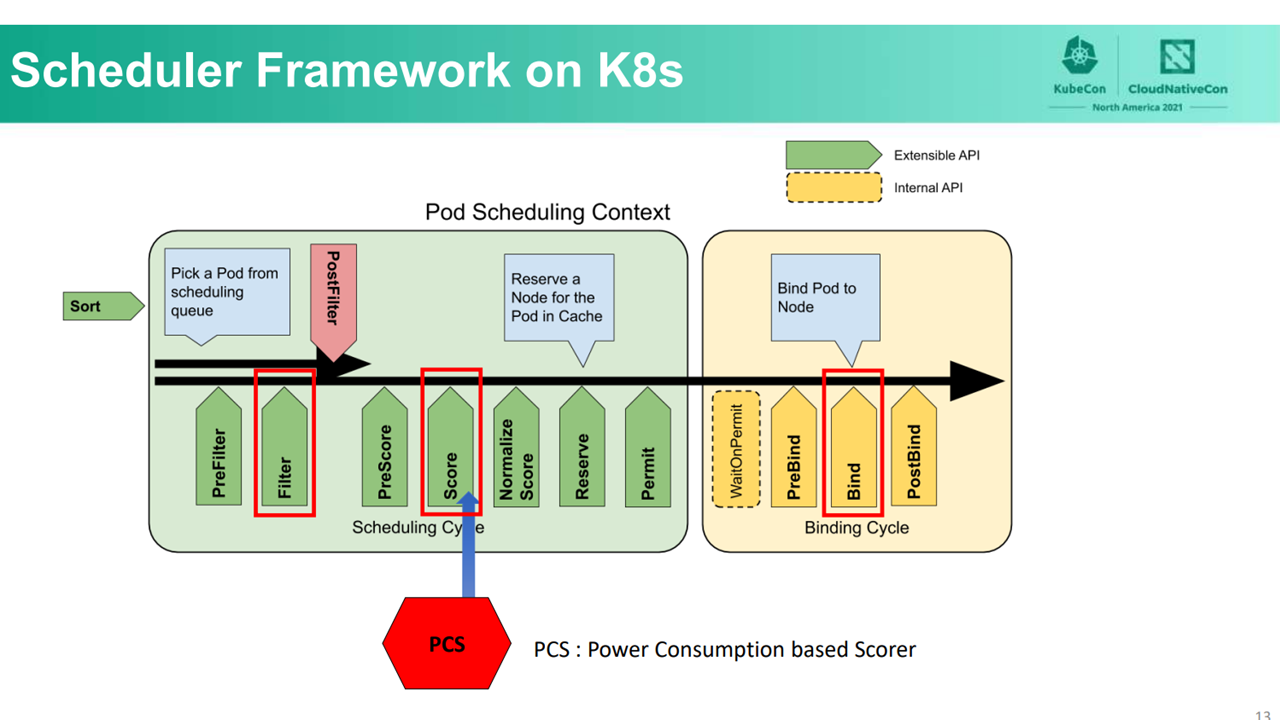 Scheduling process in kube-scheduler (Image credit)
Scheduling process in kube-scheduler (Image credit)To account for energy savings, the researchers designed a power consumption efficient control component called the Power Consumption–based Scorer (PCS) for the WAO-scheduler. The team created a neutral network–based PC model and deployed it to the TensorFlow Serving server in Kubernetes. The following table summarizes the structure and hyperparameters of the PC model.
| | CPU usage, temperature around node | |
| | | 1 hidden layer with 5,000 nodes |
| | Adam (with hyperparameters of lr=0.0005, beta1=0.9, beta2=0.999, epsilon=1e-8, decay=0.0) | |
| | mean squared error (MSE) | |
| | 256 | |
| | Power consumption of each node | |
After taking all the available nodes during the filter phase, PCS first collects information on each node, including resource usage and temperature. Next, PCS predicts the increase of power consumption in each node via TensorFlow and ranks them accordingly. In this manner, WAO-scheduler not only factors in the increased computing resources due to pods deployment, but also the increase in power consumption in each node.
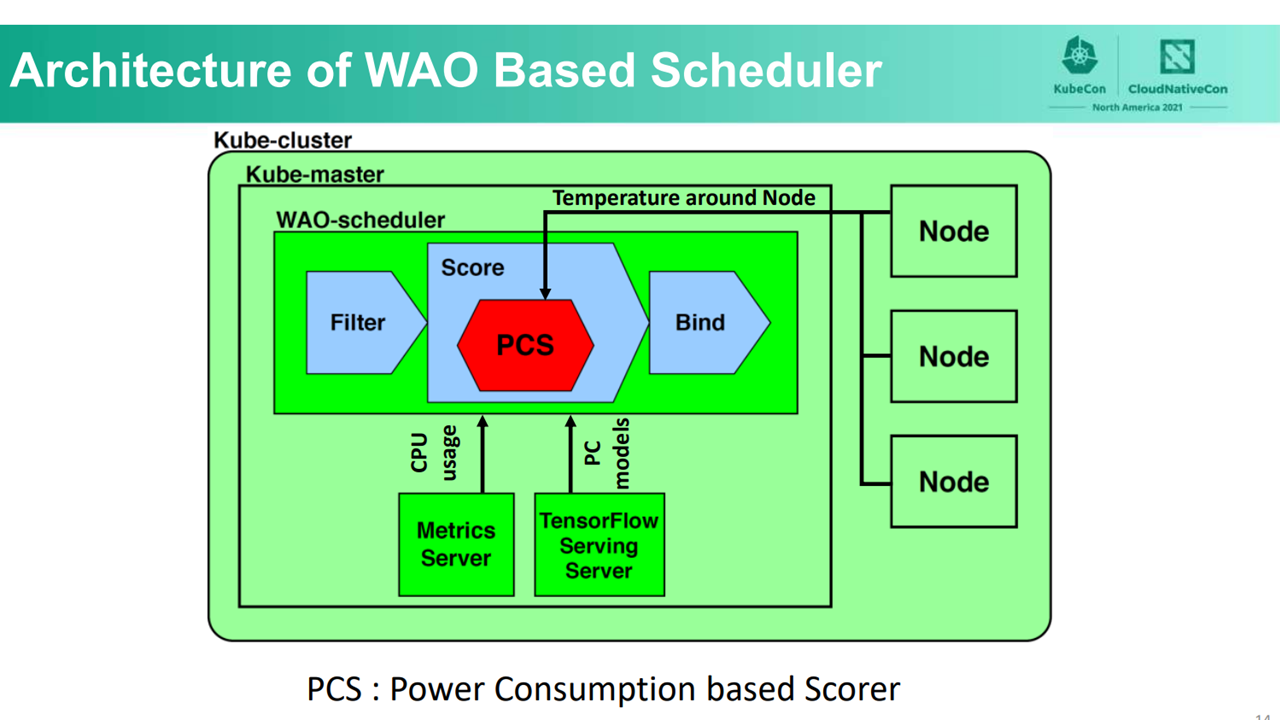 WAO-scheduler architecture (Image credit)
WAO-scheduler architecture (Image credit)WAO-LB periodically retrieves pod information using kube-apiserver. When receiving a request from a client, WAO-LB first collects information about each pod, such as CPU, memory, and network status from cAdvisor. WAO-LB then predicts the increase in power consumption applying PC and RT models. The following table summarizes the team’s implementation of the RT model.
| | CPU usage, memory information, network information, temperature around node, date-time information | |
| | | 3 hidden layers with 2,000 nodes each |
| | Adam (with hyperparameters of lr=0.0005, beta1=0.9, beta2=0.999, epsilon=1e-10, decay=0.00001) | |
| | MSE | |
| | 256 | |
| | Response time against user’s request | |
WAO-LB uses both the PC model and the RT model to evaluate the priority of clients’ task allocation to nodes based on power consumption and response times.
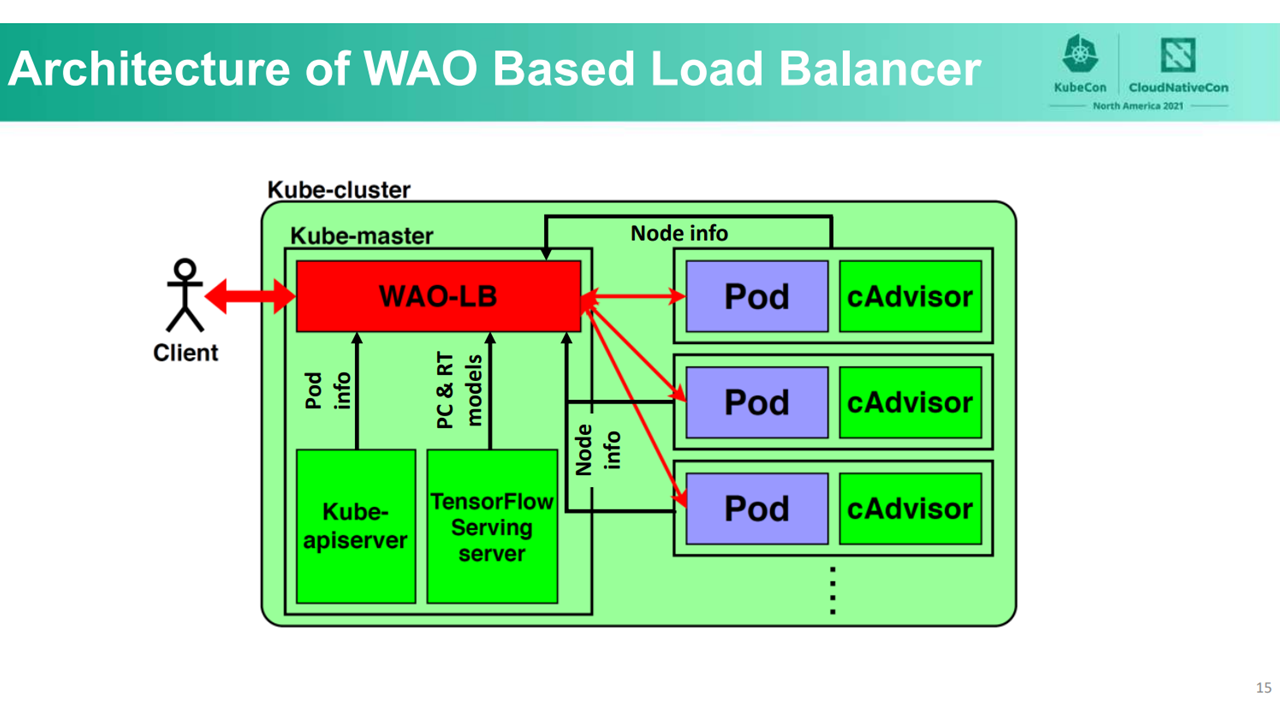 The WAO-LB architecture (Image credit)
The WAO-LB architecture (Image credit)Both the PC and RT machine learning models are based on neural networks. According to the team, neural networks performed the best when compared to other machine learning approaches, such as random forest and support vector machines.
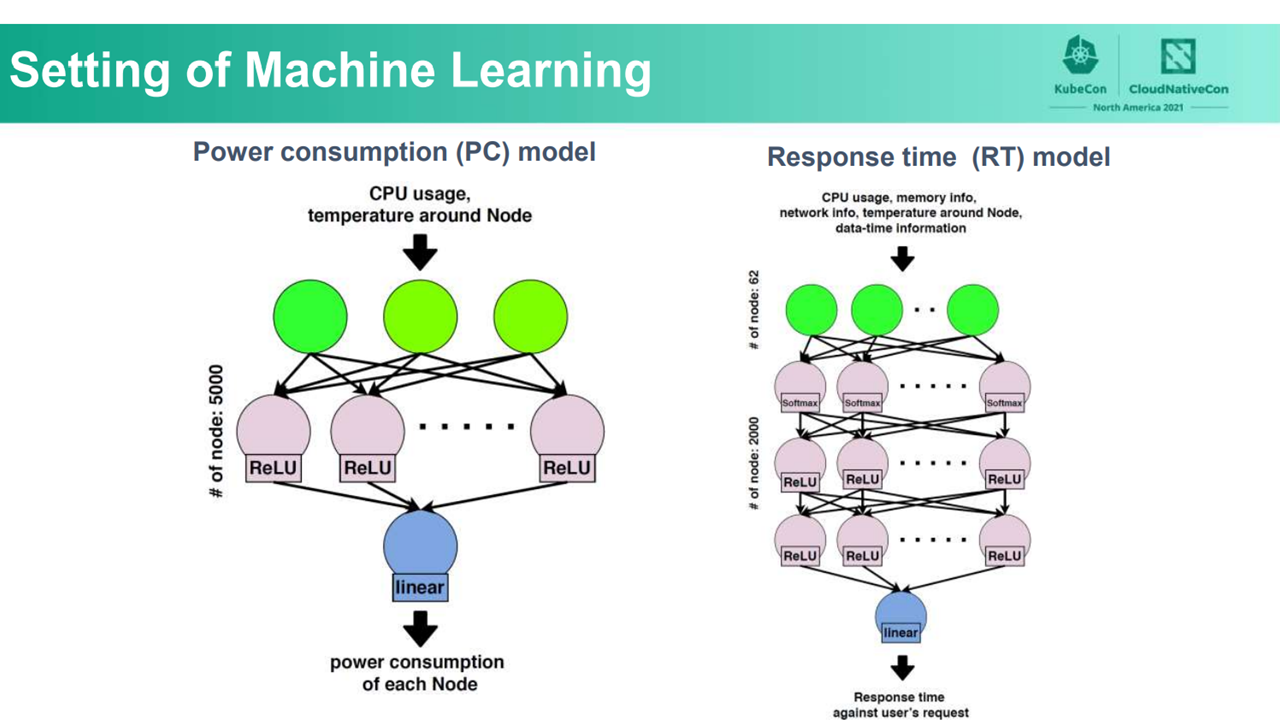 PC and RT models use neural networks (Image credit)
PC and RT models use neural networks (Image credit)
Creating a test environment
To evaluate WAO, the researchers at Osaka University tested the proof-of-concept solution on a private data center consisting of 200 Fujitsu Primergy RX2530 M4 servers. Each server was equipped with two Intel Xeon Silver 4108 CPUs (8 cores x2), 16 GB of memory, and 1 TB HDD. The edge data center is located in the Konohana Building, Osaka, Japan, of NTT West. To simulate a client in the experiment, the team used a desktop computer that was located roughly 10 km away from the data center.
Next, the team prepared a service that performs object detection based on TensorFlow. Object detection has many use cases in IoT, such as security cameras, self-driving vehicles, and mobile apps. When the service receives a compressed image from a client device, it annotates objects and organisms in the image, compress it again, and sends it back to the client device.
The power consumption value depends on both CPU usage and the temperature around the server. A server’s power consumption increased significantly when CPU usage was between 10% and 30%, Ying-Feng noted. Temperature also influenced a server’s power consumption. When temperature is low, fans will rotate at a low speed. On the other hand, when the temperature is high, fans will rotate at a higher speed.
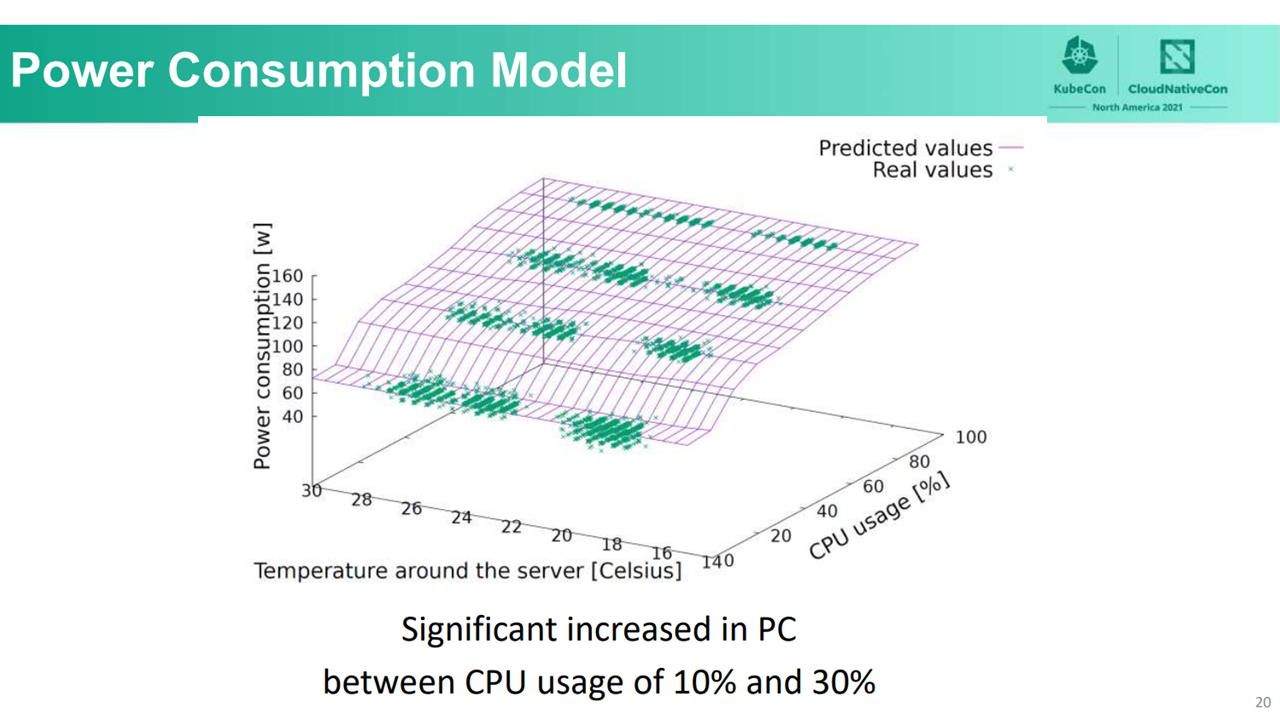 The highest power occurring at between 10% and 30% CPU usage (Image credit)
The highest power occurring at between 10% and 30% CPU usage (Image credit)With a preset temperature of 24°C, WAO-scheduler reduced more power consumption compared to other temperatures, as the server fans started to rotate if the temperature fluctuated above or below 24°C. Thus, the team went with a fixed temperature parameter of 24°C for both WAO-scheduler and WAO-LB.
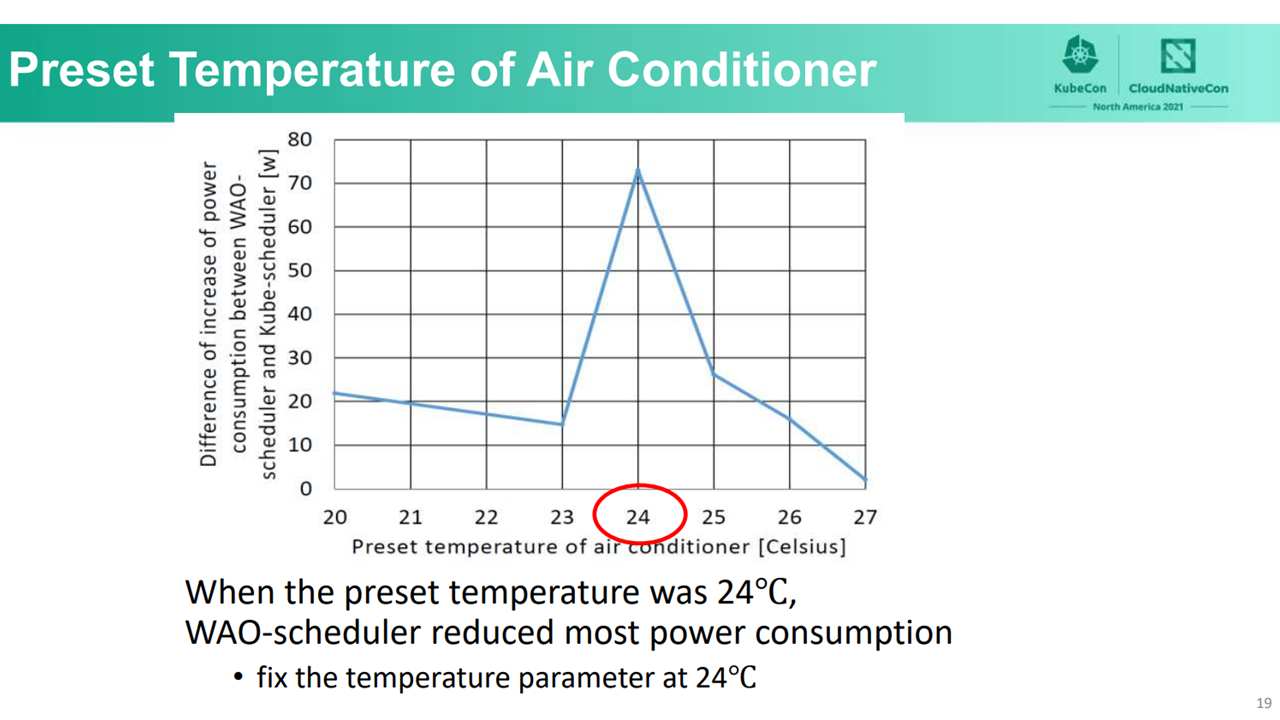 24°C as the optimal temperature for evaluation (Image credit)
24°C as the optimal temperature for evaluation (Image credit)WAO-LB uses an evaluation formula that factors in both power consumption and response times. The researchers define the formula as Evaluation Value = α*PC + β*RT, where PC and RT are power consumption and response time indices. α and β are weights of each index (α + β = 1).
“The parameter of α and β in the evaluation are weights on indices. These values can change depending on the application requirements. For example, applications related to self-driving, low response time is critical. On the other hand, for non-real-time related applications, lowering power consumption can be prioritized. In our experiment, we chose an object detection application, and we observed that a correlation of -0.569 between increased power consumption and response time [was optimal].” —Ying-Feng Hsu, Osaka University
Test results
In order to evaluate WAO, the researchers initially performed the test using kube-scheduler and MetalLB to get a baseline measurement. Next, the team ran the test under three different scenarios.
- WAO-scheduler and MetalLB
- kube-scheduler and WAO-LB
- WAO-scheduler and WAO-LB
In the first scenario, the combination of WAO-scheduler and MetalLB saved power regardless of the number of allocated pods. The team observed an 8% reduction to power consumption with 10 pods that are utilizing 20% of the CPU.
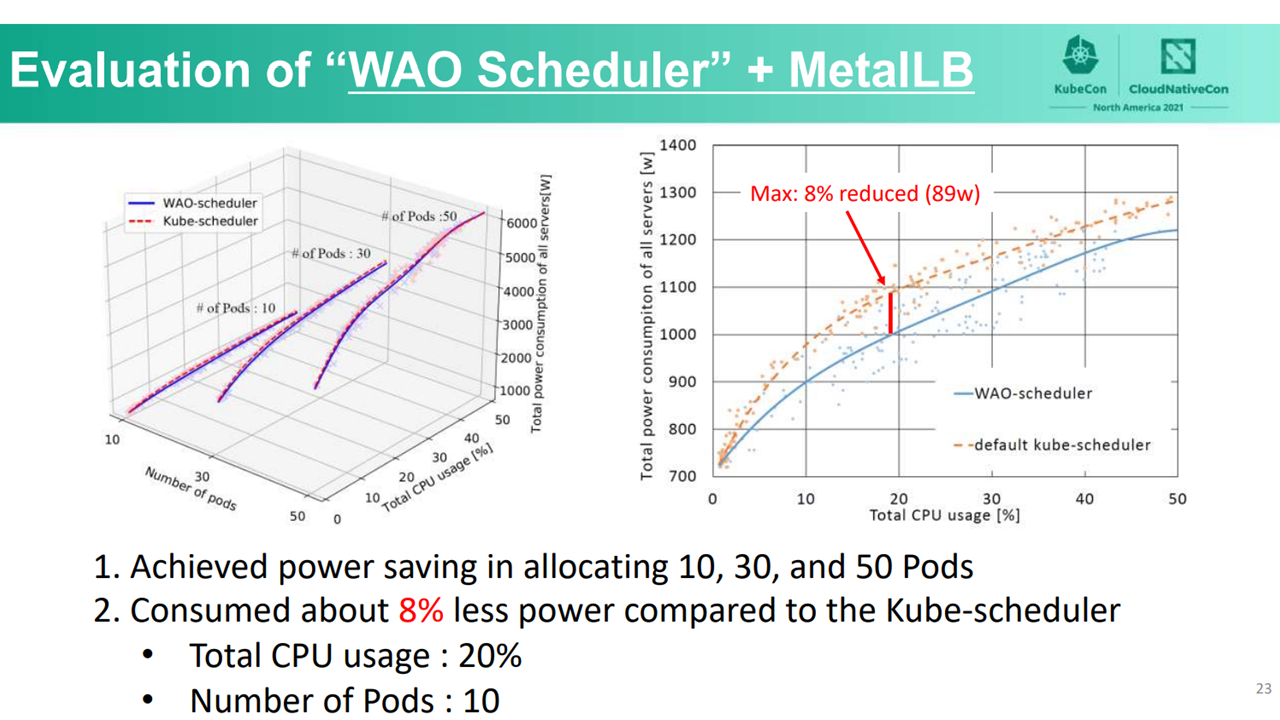 WAO-scheduler and MetalLB (Image credit)
WAO-scheduler and MetalLB (Image credit)In the second scenario, the combination of kube-scheduler and WAO-LB saved power, except when response time is heavily weighted. When power consumption is prioritized, the team saw a 9.9% reduction to power consumption at a total CPU usage of 20%.
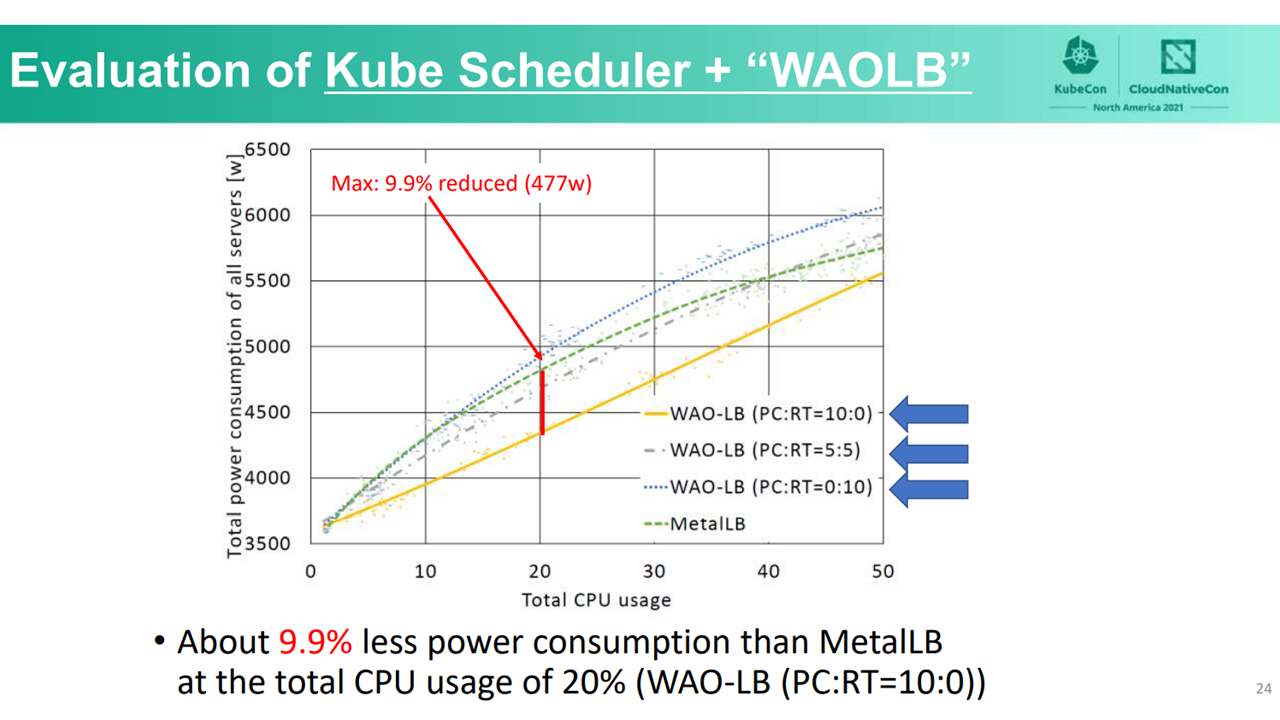 kube-scheduler and WAO-LB (Image credit)
kube-scheduler and WAO-LB (Image credit)In the third scenario, the complete WAO solution was able to achieve a 13% reduction to power consumption at a total CPU usage of 27%.
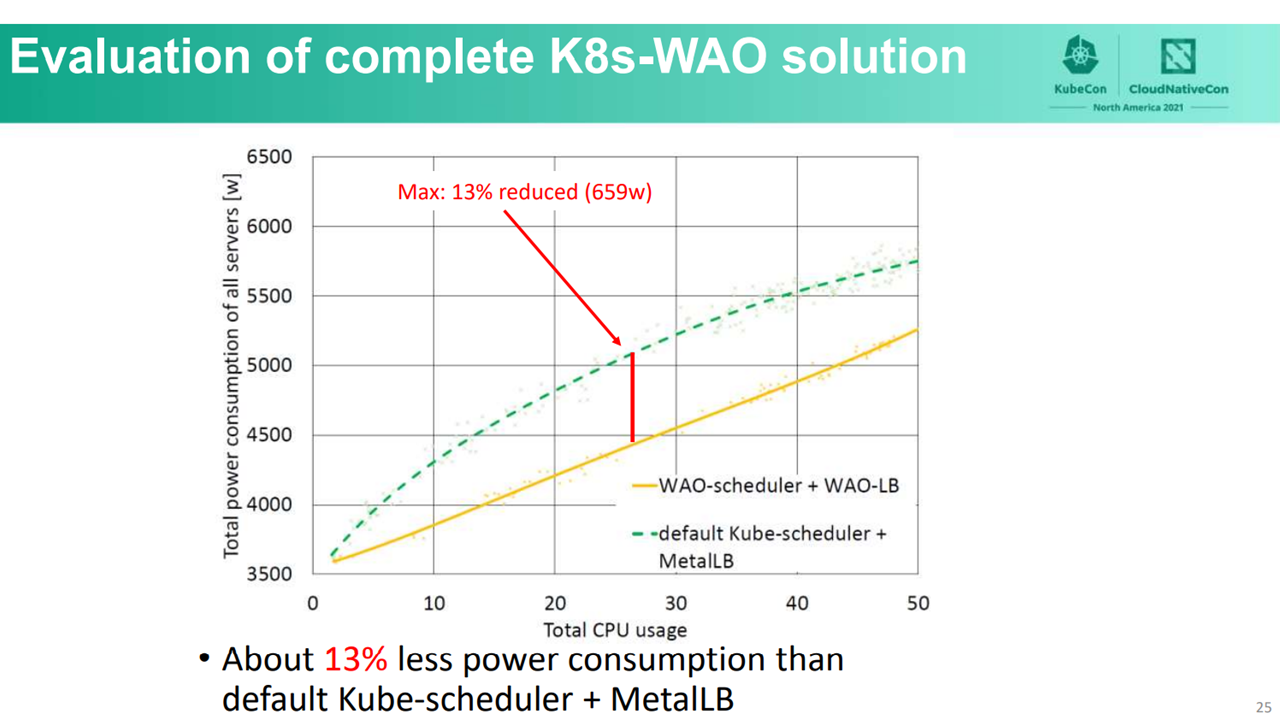 WAO-scheduler and WAO-LB (Image credit)
WAO-scheduler and WAO-LB (Image credit)After the tests, the researches concluded that WAO-scheduler and WAO-LB can achieve the highest power consumption reduction rates at a total CPU usage between 15% and 39%.
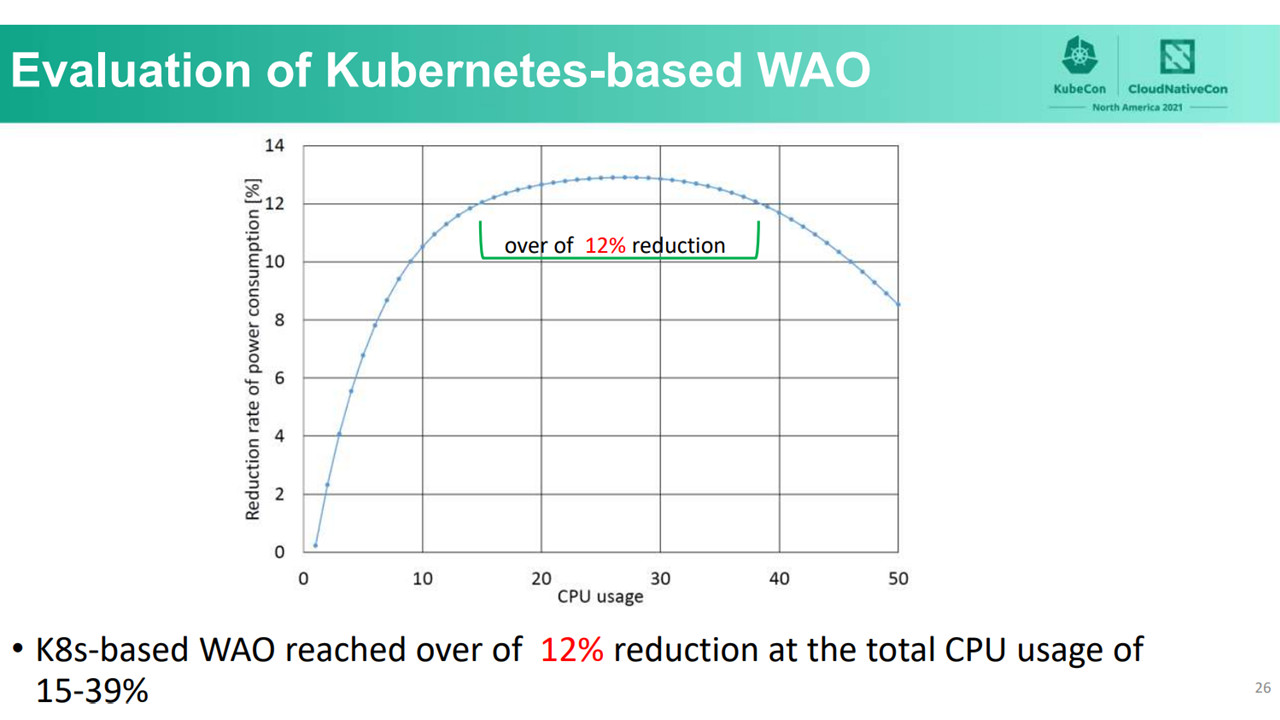 Power consumption rate (Image credit)
Power consumption rate (Image credit)“In general, [CPU] utilization in a typical data center is often between 20% and 40%. This result tells us that the proposed Kubernetes-based WAO can achieve the highest power consumption reduction under a common data center CPU usage scenario.” —Ying-Feng Hsu, Osaka University
Besides the reduction in power consumption, WAO was able to achieve faster response times, except when power consumption is heavily weighted.
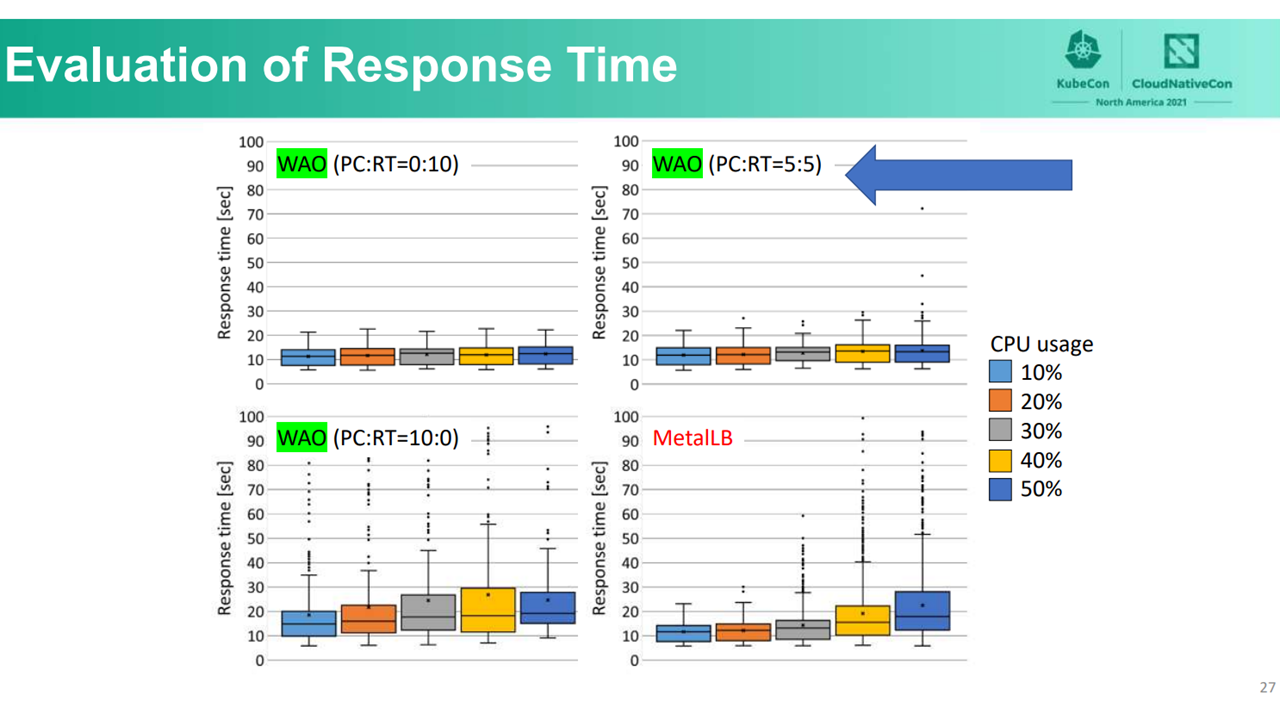 Response time test results (Image credit)
Response time test results (Image credit)As edge computing becomes more widespread, power consumption in data centers will continue to increase. Solutions like WAO can provide organizations with a tool for managing resources and costs related to power consumption. Read more about WAO in the Osaka University paper.
Want details? Watch the video!
Ying-Feng Hsu provides an overview of the workload allocation optimizer and how it can reduce power consumptions in data centers.
Further reading
- Shell Builds 10,000 AI Models on Kubernetes in Less than a Day
- Denso Delivers an IoT Prototype per Week with Kubernetes
- The Pompeii Museum Develops a Mobile App on Kubernetes in Six Weeks
About the expert

Ying-Feng Hsu is Assistant Professor at Matsuoka Laboratory, Osaka University. His research revolves around machine learning and cloud computing, with a special focus on the use of data center operation, power consumption optimization, and network intrusion detection systems. In the past, Ying-Feng has worked as a data science expert on national projects, such as Pediatric Health Information System (PHIS) and Project Tycho.

