ML Toolkit for TensorFlow: Out-of-the-Box Algorithms to Boost Training Data by 50x

A variety of algorithms
At TensorFlow Dev Summit 2017, Ashish Agarwal of Google introduced a TensorFlow-based toolkit of machine learning algorithms. The toolkit provides out-of-the-box packed solutions to enable researchers and developers to create high-level custom model architectures.
According to him, ML Toolkit is open-sourced to be actively developed and now offers the following set of algorithms:
- Linear / logistic regression
- K-means clustering and Gaussian mixture model for unsupervised clustering of data
- WALS matrix factorization, a popular collaborative algorithm for the computer systems
- Support vector machine
- Stochastic dual coordinate ascent for context optimization
- Random forest and decision trees
- Neural networks (DNN, RNN, LSTM, etc.)
Ashish highlighted some details on a few algorithms, so the attendees could better understand the existing and upcoming features for them.

Clustering: k-means and GMM
Working with k-means, the team has implemented a standard layouts iterative algorithm along with random and k-means++ initializations. A support for full- and mini-batch training modes is enabled, and a user can specify such distance functions as cosine or Eucledian square distances.

Gaussian mixture models (GMM) represent more powerful model, yet harder to train. To facilitate the process, an iterative expectation-maximization algorithm was utilized. Furthermore, one can choose from a combination of means, covariances, and mixture weights to train on.
WALS
WALS is a matrix factorization using weighted alternating least squares. Let say, you have a sparse matrix comprising ratings that users have given some videos. As the matrix is sparse, it means that not all videos have been rated by all users. So, you want to build recommendations which video to watch next or find user-user / video-video similarities. For that purpose, one has to factorize the matrix into two dense factors.

As the algorithm indicates, the loss is weighted, allowing for downgrading unrated videos in the original input, avoiding spam, or popular entries from drowning out the total loss.
Support vector machine
Support vector machines (SVMs) operate by finding a decision boundary that maximizes a margin. The Google team employs soft margin methods using a hinge loss with current implementation of linear SVMs with L1 and L2 regularizations.
With a nonlinear kernel, SVMs get more powerful as it allows for finding a complicated decision boundary. So, now Google is working on providing nonlinear kernels using the kernel approximation trick.
Stochastic dual coordinate ascent
Using a neat trick, stochastic dual coordinate ascent (SDCA) transforms, let’s say, a convex loss function with L1 and L2 regularization into a dual form, which proves efficient in most cases. This algorithm is capable of delivering models from linear and logistic regressions to SVMs.

Random forests
Random forests are basically decision trees that create a hierarchical partitioning of the feature space. Currently, the method behind is “extremely random forest training,” which enables better parallelization and scaling. Google Brain is also working on delivering gradient-boosted decision trees.
Estimator API
To make those algorithms easy to implement, the team employs Estimator APIs. Ashish demonstrated how it works when applied to k-means clustering. The reason for using an estimator API is that it significantly boosts the process with just a few lines of code.

“You start by creating a k-means clustering object, and you can pass in a bunch of options, like a number of clusters, how you want to train, how you want to initialize, and so on. Next, you call the fit function and pass it into your input, and that’s it. No tons of logs behind the scenes.” —Ashish Agarwal, Google Brain
On creating a graph, the estimator will run training iterations and configure the runtime until the training is done. Then, a user can proceed with inspecting the model parameters, start running inference, find assignment to clusters, etc.
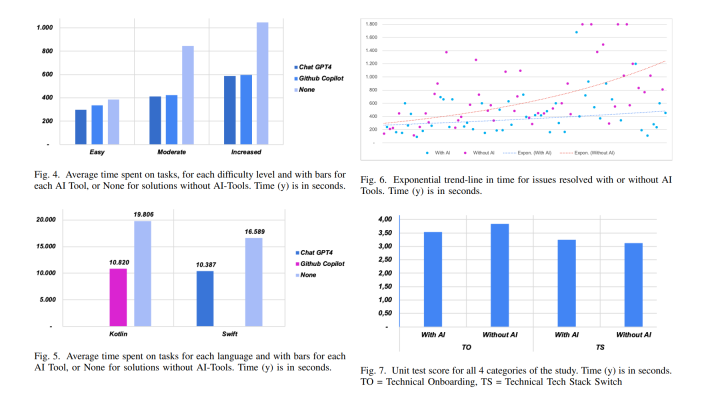
Furthermore, a user can do more than just inspect the graphs, but embed them into larger training models. Ashish exemplified embedding the k-means algorithm as a layer into a bigger deep learning network.
He also provided sample code for implementing this.

Distributed implementation
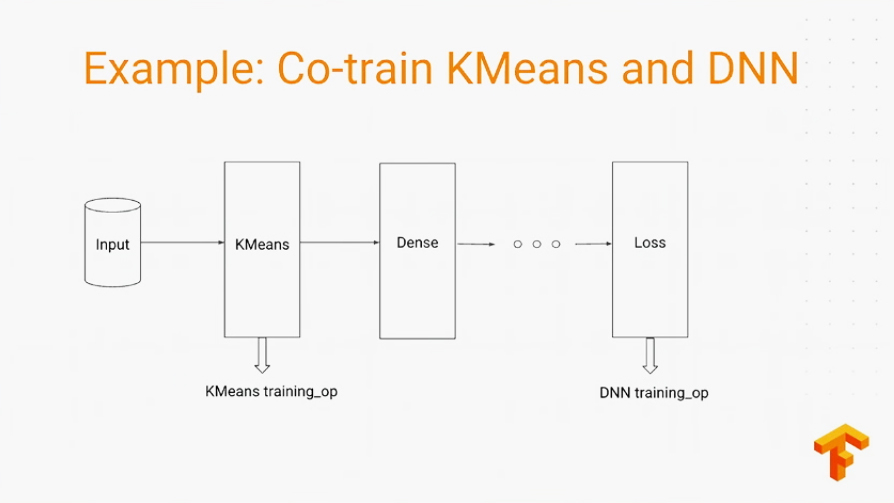
Breaking it down to just a few lines of code, those algorithms are backed up by distributed implementations.
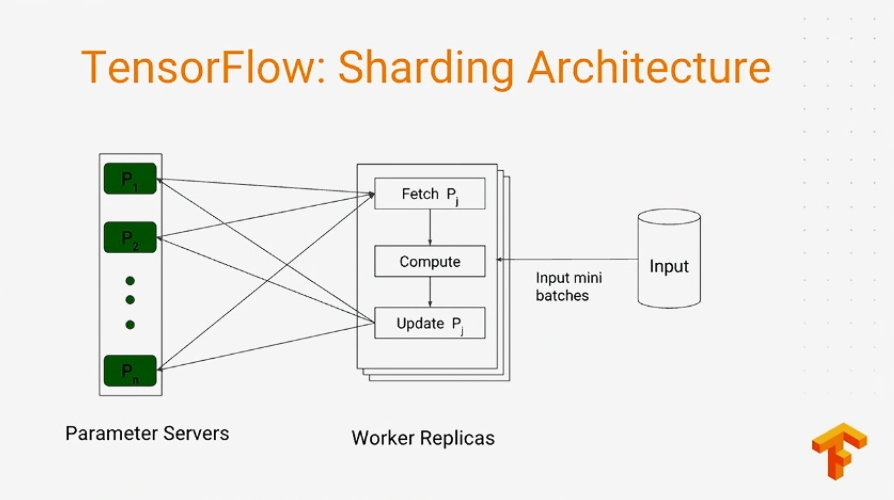
So, Ashish also showed how it works behind the WALS algorithm.
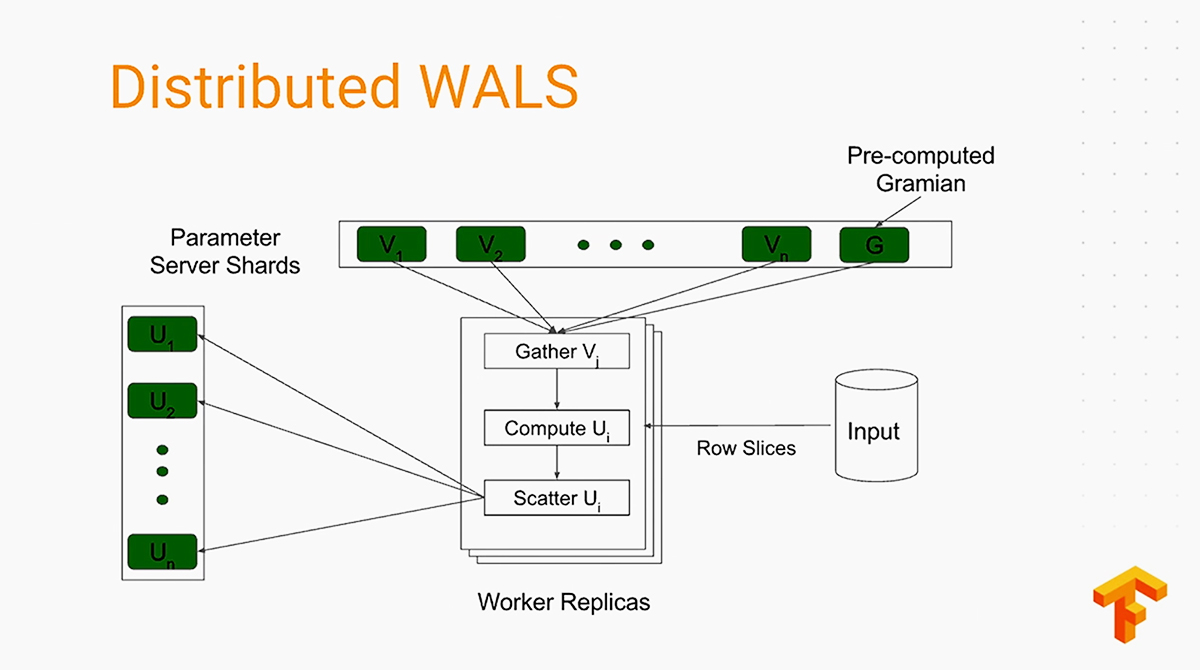
In practice, it delivers unsurpassed performance, so you can seamlessly run training across hundreds of thousands of machines.
“For example, with random forests we were able to train thousands of trees with billions of nodes. With SDCA, we saw 10x–50x faster convergence compared to Google’s internal SDC implementation of logistic regression with billions of examples. ” —Ashish Agarwal
According to Ashish, the distributed WALS algorithm allowed for factorizing the 400M*600M sparse matrix into 500 dimensional factors in just 12 hours. It is 50x better scaling than the earlier MapReduce-based implementation offered.
Want details? Watch the video!
More from TensorFlow Dev Summit:
- Using TensorFlow to Compose Music Like the One of Bach or The Beatles
- Ins and Outs of Integrating TensorFlow with Existing Infrastructure
About the expert
Ashish Agarwal is actively involved in extending and applying TensorFlow to improve such core Google products as Search Ads. Before this, he spent many years building Search Ads foundations, from machine learning signals to the ads auction, and also created a Google-wide live traffic experimentation framework.