
Migrating Pivotal Cloud Foundry to a Multi-AZ Deployment

This post describes how we moved an up-and-running PCF installation from a single availability zone deployment to multiple AZs for one of the earliest adopters of the platform.
Issues during migration
The customer had been using PCF starting from version 1.0 and eventually ran out of resources to support its deployments. Our task was to create a multi-AZ deployment while migrating all the company’s environments to a wider network infrastructure. The moved PCF installation ran on VMware vSphere 6. Each deployment consisted of around 100 Diego Cells with an average memory usage of over 80% of Diego Cell capacity.
Having examined the customer’s environment, we faced the following issues:
- Clusters would most likely fail during the migration. The MySQL cluster would get a split-brain state, the Consul cluster wouldn’t be able to find routes, and the etcd cluster would fail, too.
- Pivotal CF tiles, except for the Elastic Runtime tile and the MySQL tile, were not supposed to be moved. The RabbitMQ tile, for example, would fail to move and the RabbitMQ cluster would be destroyed.
- With memory usage for Diego cluster exceeding 80%, most of the application instances and applications would be unavailable.
- Changing network for service brokers would cause the Service Unavailable error, and applications wouldn’t be able to reconnect.
- Any Pinned IPs for routers, proxies, etc. had to be removed from PCF to be able to apply changes.
 Image credit: Pivotal
Image credit: Pivotal
Workarounds
The revealed obstacles rendered plenty of room for exercising our troubleshooting skills:
- To address the cluster failure problem, we reduced the quorum to one-node clusters.
- During the migration, the Diego cluster memory capacity had to be more than 20% of the total amount of memory resources to prevent applications from failing. We added more Diego Cells to the cluster to decrease memory usage to 50%.
- PCF v1.7 had no option for setting custom Diego Cell instance sizes. Some of the instance parameters in the Resource Config settings were ill-fitting from the System administrator’s point of view and needed to be changed. For example, the 2xlarge.mem instance was using four CPUs and 64 GB of RAM, while best practice for CPU/memory ratio is one to four. Therefore, we added more size to this instance to get a 16 CPUs / 64 GB of RAM ratio using these API docs. This also caused a problem with application instances. During Diego Cell resizing, most of the app instances were down; however, that didn’t cause any application DoS.
- MySQL monitor job may also fail and return an error. This happens when MySQL monitor is trying to find the
uaa.CF_DOMAINroute which is not available. The main reason for such a failure is that the Consul database is damaged and the routes are missing. To fix this error, you need to recreate the Consul database as described here.
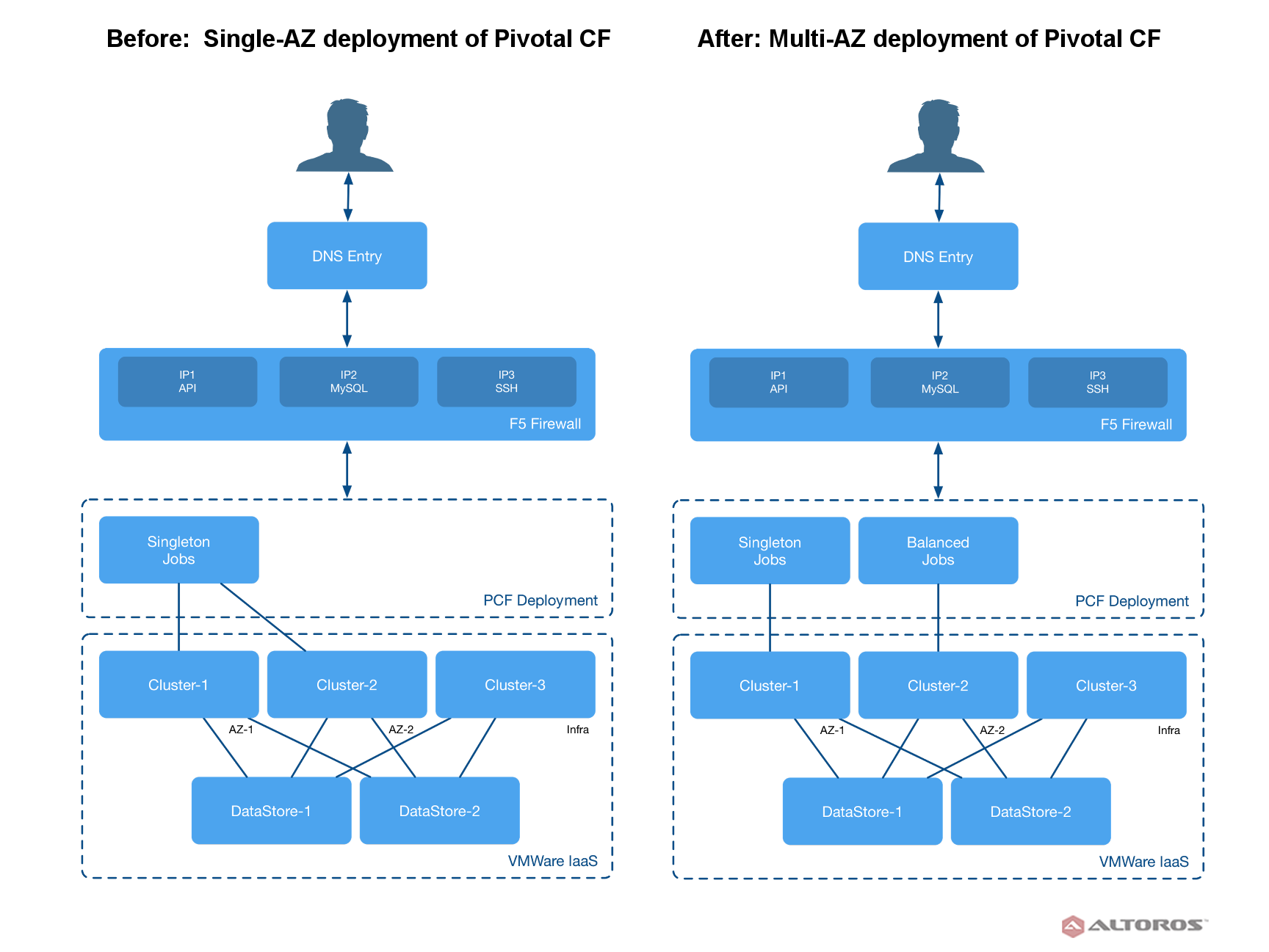
Steps for migration
So, the complete process of moving to a multi-AZ deployment included the following steps:
- Reducing the quorum of all clusters (Consul, etcd, MySQL, etc.) to a single node
- Updating cluster info in the Ops Manager Director
- Adding a new availability zone to the Ops Manager Director
- Assigning a network to the newly created availability zone
- Unlocking PCF tiles using this approach
- Selecting the new availability zone as a balance zone
- Removing all secondary Pinned IPs for routers, HAProxy, and MySQL
- Restoring the quorum back to three-node clusters
- Running errand jobs
Lessons learned
When moving your PCF platform to a multi-AZ deployment, note these tips:
- Make sure the quorum for clusters is reduced to one node.
- When applying changes, watch the Consul server and be ready to recreate the Consul DB to recreate all routes.
- Pay attention to the MySQL cluster for Elastic Runtime (ERT).
- After introducing a new change, verify that you’ve clicked the Apply Changes button.
- Do not try to move any tile, except for the ERT tile, to multiple networks. Also, make sure that you have removed any Pinned IPs before moving ERT to two networks and multiple AZs.
Migrating BOSH to a different network
In case of a misconfiguration during initial deployment, or when redeployment is not possible, or if a network range depleted, you may also need to move BOSH to a new network range and then migrate Pivotal CF.
In our case, the migration was required for all PCF deployments, since the current network resources were depleted and the customer wasn’t able to increase the number of Diego Cells or any other PCF Elastic Runtime components and tiles. All the current environments were deployed on VMware vSphere and used an external Load Balancer.
To migrate BOSH successfully, we created the following runbook:
- Enable BOSH dual homing relying on this documentation.
- Unlock PCF tiles and change the default deployment network for BOSH using this guide.
- Since Ops Manager won’t support applying changes when the BOSH network is changed, introduce modifications to the Validation process.
- As soon as BOSH is moved, unlock tiles and change the network for ERT, as well.
Revealed problems and workarounds:
- Ops Manager wouldn’t allow us to move BOSH to a different network, and the validation process would fail. As a workaround, we changed
bosh_director_job_ip_inertia_verifier.rb. This gem checks if the BOSH Director IP changed and compares it with the current state of the BOSH deployment. - Having changed the BOSH network and having implemented BOSH dual homing, we faced a problem that the ERT components were not able to talk to the BOSH Director through the Agents. The solution was to edit the
bosh.ymlfile manually and specify new network components (DNS, Gateway). This step required starting bosh-init manually. With bosh-init, all the ERT components were still available, and BOSH was able to manage all jobs. - Trying to disable BOSH dual homing would result in complete unavailability of the ERT deployment, making the BOSH Director unable to reach it. To prevent this, we ran
bosh deploy DEPLOYMENT_MANIFESTmanually after the BOSH Director was moved to the new network. During this step, thesettings.jsonfile for the Agent was updated with a new BOSH Director IP. After that, BOSH dual homing could be disabled. - We also faced a problem related to quorum in clusters, including Consul, etcd, MySQL, etc. As a workaround, we reduced the quorum in these clusters to one node before introducing any changes. As soon as BOSH dual homing was disabled, the clusters were restored back to three nodes.
- In some cases, the Cloud Controller (CC) worker and CC itself would go down. To fix this issue, we had to power-cycle them. The issue was caused by the NFS mount point. During
bosh deploy, the NFS IP was changed and the Cloud Controller worker and CC were not able to unmount it.
Moving Pivotal Cloud Foundry deployment is a relatively easy task, but workarounds are inevitable. Just hold to the outlined recommendations and be prepared to tackle issues down the road.





