
Mastering Game Development with Deep Reinforcement Learning and GPUs

Deep Q-learning on GPU
Deep learning solutions has penetrated multiple industries with a view to improve our everyday experiences. Deep learning is employed in translation, medicine, media and entertainment, cybersecurity, automobile industry, etc.
At a recent TensorFlow meetup in Denver, Eric Harper of NVIDIA explored the world of deep reinforcement learning, highlighting the areas it is applied at, diving into the underlying algorithms and approaches. He also outlined how GPU-based architecture may help to improve model training.
With the Big Bang in artificial intelligence—initiated through combining the powers of deep neural networks, big data, and GPU—the modern AI scene counts dozens of companies behind revolutionary products, as well as 1,000 startups with $5 billion in funding (according to Venture Scanner).
The notion of deep reinforcement learning has got into the spotlight with Google’s DeepMind utilizing the approach to master Atari games. What they did was go beyond just classifying, but teach the model to take actions in an environment and learn from observing the results of the actions.
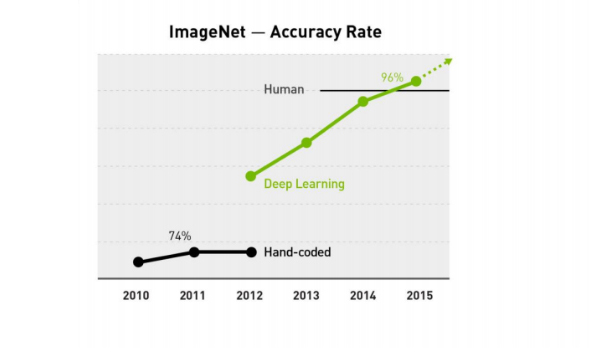 The accuracy rate of ImageNet (Image credit)
The accuracy rate of ImageNet (Image credit)In 2016, DeepMind’s AlphaGo—a narrow AI program designed to play the Go board game—outplayed the world’s champion Lee Sedol. So, what was behind AlphaGo?
- 40 search threads
- 1,202 CPUs
- 176 GPUs for inference only
The training took around three weeks on 50 GPUs for the policy network and another three weeks for the value network. Eric mentioned there were rumors around that AlphaGo had achieved the excellence of doing inference on just a single GPU.
How does it all happen to work?
In terms of classical reinforcement learning there is an agent acting in an environment, which it can influence by taking actions. A policy determines actions, while an environment returns a reward and a state. To find a policy that maximizes a reward, one can employ Q-learning.
However, reinforcement learning has it own drawbacks:
- state spaces are too large
- its capabilities are limited by the need “for hand-crafted, task-specific” features
- finally algorithms to learn and generate data are required
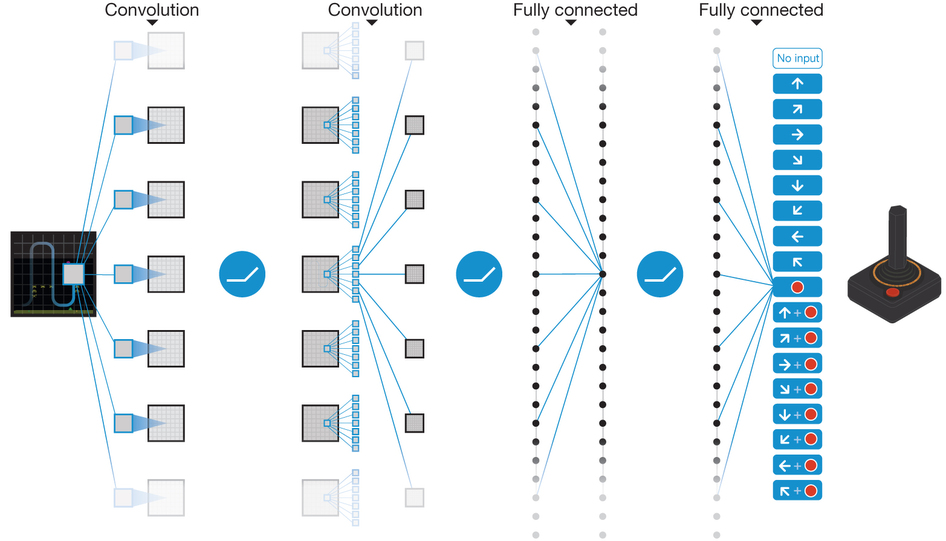 Schematic illustration of a convolutional neural network (Image credit)
Schematic illustration of a convolutional neural network (Image credit)To combat the trouble of too many states and/or actions stored in memory and speed up the process of learning the value of each state, one can make use of value function approximation. It also enables to make predictions on previously unseen states.
When dealing with Q-learning, one may face instability due to correlated trajectories. Here deep Q-learning networks come in. What one has to do is:
- Take an action according to the ep-greedy policy
- Store transition in replay memory
- Sample mini-batch from memory
- Compute Q-learning targets to old parameters
- Optimize Q-network vs. Q-learning targets using Stochastic gradient descent
Eric also touched upon policy-based reinforcement learning, which sometimes simplifies the process of computing a policy in comparison to the value-based approach. For example, in the Pong game if a ball is coming toward you, you hit it (value-based). If you hit the ball coming towards you, you’ll get a one-point reward later (policy-based). This approach can feature better convergence properties and is effective in high-dimensional or continuous action spaces as you don’t have to find maximal values.
Accelerating further with the A3C algorithm
In June 2016, DeepMind released the Asynchronous Advantage Actor-Critic (A3C) algorithm that is capable of achieving better scores on a bunch of deep reinforcement learning tasks faster and easier.
Within the A3C algorithm, each worker is a separate process. It starts with adjusting network parameters to the global network. Then, a worker interacts with an environment, storing a list of its experiences. Once the number of experiences is sufficient, a worker calculates value and policy losses and gradients to further update the global network.
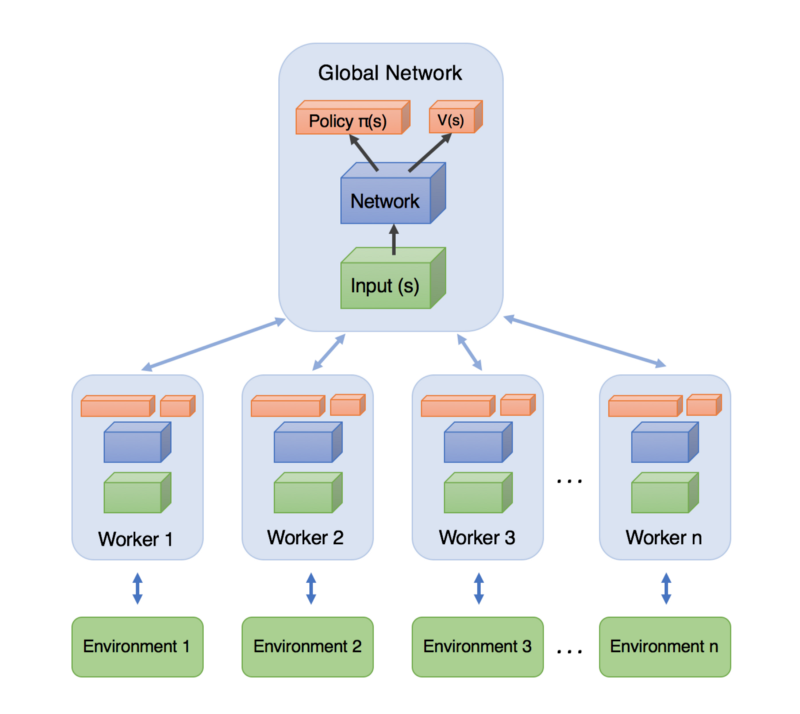 A high-level architecture of A3C (Image credit)
A high-level architecture of A3C (Image credit)What comes out of using this algorithm on GPU?
- A predictor submits predictions in batches to the model on the GPU and returns the requested policy.
- A trainer submits training batches to the GPU for model updates.
- Performance on the GPU is optimized when the application has large amounts of parallel computations that can hide the latency of fetching data from memory.
- By increasing the number of predictors, one can achieve faster fetching prediction queries. However, smaller prediction batches result in more data transfers and lower GPU utilization.
- A bigger number of trainers leads to more frequent model updates. Note: too many trainers can occupy GPU and prevent predictors from accessing it.
- More agents generate more training experiences while hiding prediction latency.
- Training per second is roughly proportional to the overall learning speed.
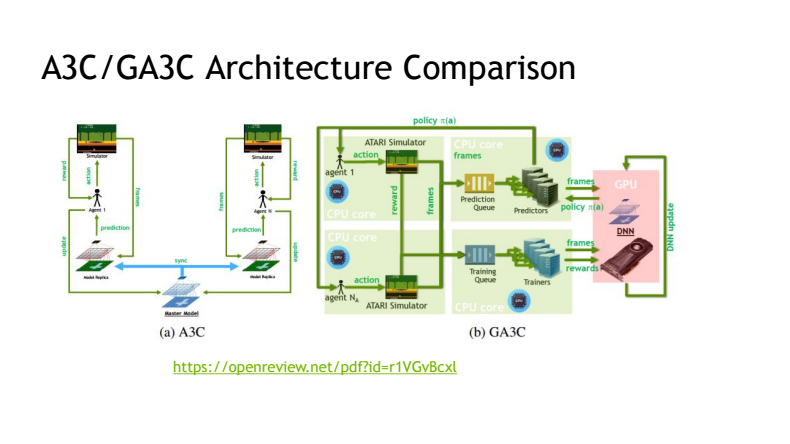 The architecture comparison of the A3C and GA3C algorithms (Image credit)
The architecture comparison of the A3C and GA3C algorithms (Image credit) Being one of the major forces driving artificial intelligence forward, Google has recently released a tensor processing unit (TPU) designed specifically to boost machine learning performance. With all those options at hand, we actually see future happening here and now.
Want details? Watch the video!
Related slides
Further reading
- Deep Q-Networks and Practical Reinforcement Learning with TensorFlow
- What Is Behind Deep Reinforcement Learning and Transfer Learning with TensorFlow?
- Learning Game Control Strategies with Deep Q-Networks and TensorFlow
- Performance of Distributed TensorFlow: A Multi-Node and Multi-GPU Configuration
About the expert
Eric Harper is a Data Scientist and Solutions Architect for NVIDIA with a focus on deep learning for enterprise. Prior to NVIDIA, he was a Lead Data Scientist for DISH Media Sales and before entering the industry Eric also served asa Postdoctoral Researcher in Low-Dimensional Topology at McMaster University and the University of Quebec at Montreal.


