Improving Facial Recognition with Super-Fine Attributes and TensorFlow

Identification without facial recognition
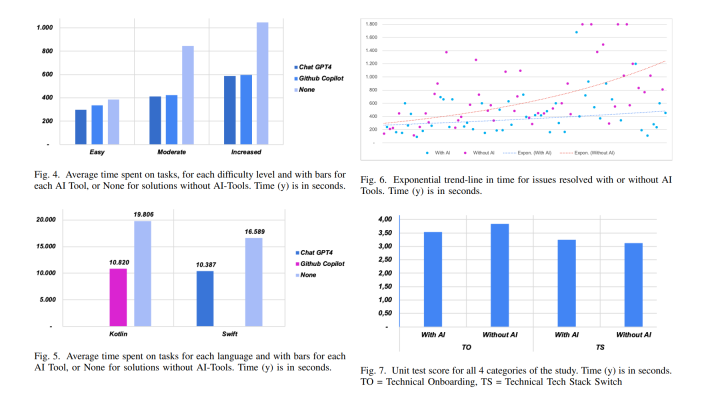
On April 15, 2013, a tragedy befell the annual Boston Marathon as two homemade pressure cooker bombs detonated near the finish line. There were several hundred casualties reported after the incident.
Law enforcement surveillance teams scoured images and videos of the marathon to find suspects. Three days later, the Federal Bureau of Investigation (FBI) released images of two men who were later identified as the terrorists responsible for the bombing.
 Faces aren’t always seen on camera (Image credit)
Faces aren’t always seen on camera (Image credit)
Daniel Martinho-Corbishley
At a recent TensorFlow meetup in London, Dr. Daniel Martinho-Corbishley, CEO at Aura Vision Labs, exemplified this investigation and explained why it may took some days to search. “Faces are really hard to spot in crowds,” he said. Additionally, not all images and video footage contain faces depending on the camera angle and position.
“Surveillance teams all over the world spend hundreds of thousands every year just crawling through video footage. This problem is about to get worse because Internet video surveillance is looking to grow seven times in the next three years. We need to find a way of identifying people without being able to see their faces.” —Dr. Daniel Martinho-Corbishley
Though hard biometrics—facial recognition, DNA detection, iris scanning, and fingerprint analysis—can uniquely identify a person, they are very difficult to capture. So, are there alternative methods of recognizing an individual? At the meetup, Daniel introduced the attendees to the method of super-fine attributes, which relies on using soft biometrics rather than hard ones and can serve as a solution to the problem.
Precise image labeling with super-fine attributes
Soft biometrics use multiple visual cues—such as gender, age, height, weight, build, hair color and length, skin color, clothing, etc.—to create a unique description that can identify a person. Unlike hard biometrics, soft ones can be seen from a distance regardless of image quality and a person’s angle or pose. This makes soft biometrics far better candidates for recognition goals.
 Soft biometrics can be used on low-quality images (Image credit)
Soft biometrics can be used on low-quality images (Image credit)“Hard biometrics are as great as they’re very discriminative. You can have one that can uniquely identify someone most of the time, but they’re really hard to capture. You can’t capture them with a CCTV image. Soft biometrics are the opposite, you can see a lot of soft biometrics in blurry and grainy images.” —Dr. Daniel Martinho-Corbishley, Aura Vision Labs
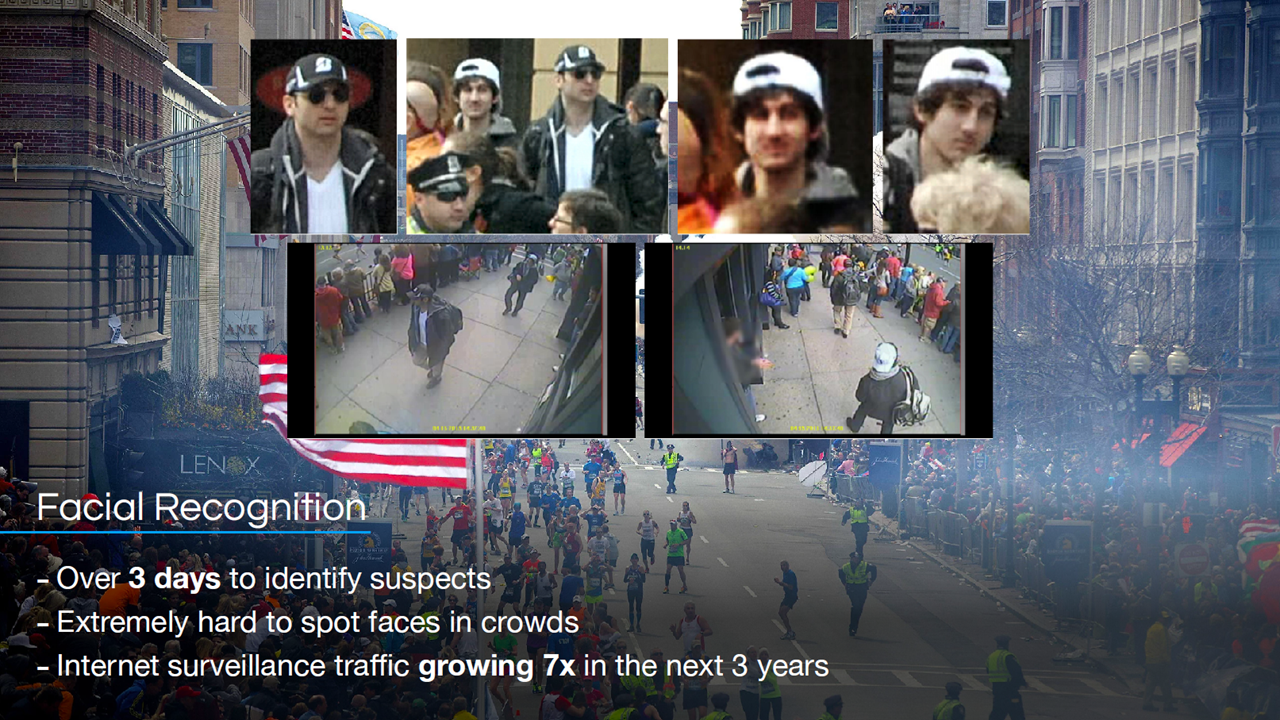
To label images properly with soft biometrics, Daniel introduced the concept of super-fine attributes. According to the study, super-fine attributes simultaneously encapsulate multiple, integral concepts of a single trait as multi-dimensional coordinates. This enables more intricate image descriptions, which categorical or binary attributes cannot account for.
 Super-fine attributes can categorize obscure images (Image credit)
Super-fine attributes can categorize obscure images (Image credit)For instance, super-fine attributes can be used to label a blurry image that somewhat looks like a female as “obscure, but vaguely female.” These labels are linked to the coordinates in the super-fine space, so visually similar images are closer to one another.
“We want to move from the (categorical/binary space) to a super-fine attribute space. It’s just projecting images as multi-dimensional coordinates in a continuous space, rather than having them as fixed binary or categorical labels. It’s a more objective way of comparing the similarities and differences of different types of images.” —Dr. Daniel Martinho-Corbishley
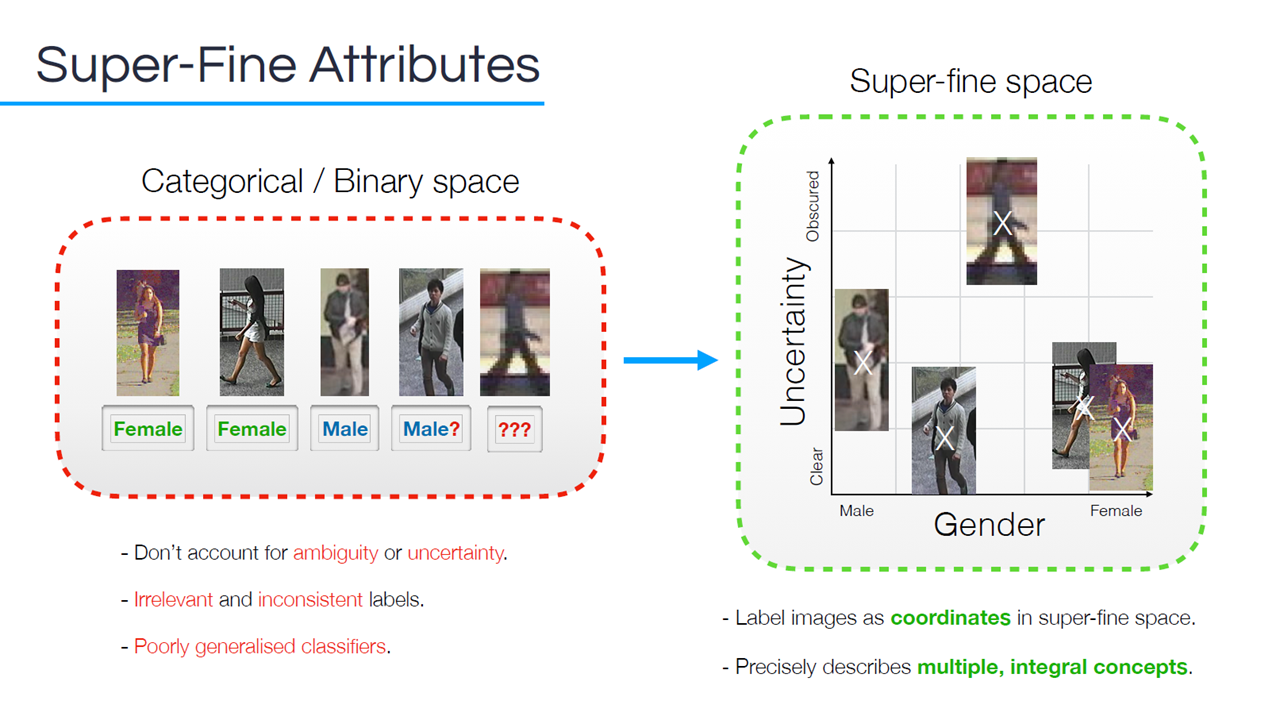
To create a super-fine space, crowd prototyping can be used. With this approach, an image is crowdsourced to discover visual labels and their relationships. In the following example, pairwise similarities are crowdsourced between two images at a time. The differences in each image forms a high-dimensional distance matrix, which is then used to create an embedding strategy. A clustering algorithm can then be employed to identify labels.
 A crowd prototyping methodology (Image credit)
A crowd prototyping methodology (Image credit)Once the super-fine space has been identified, new images are labeled into the space.
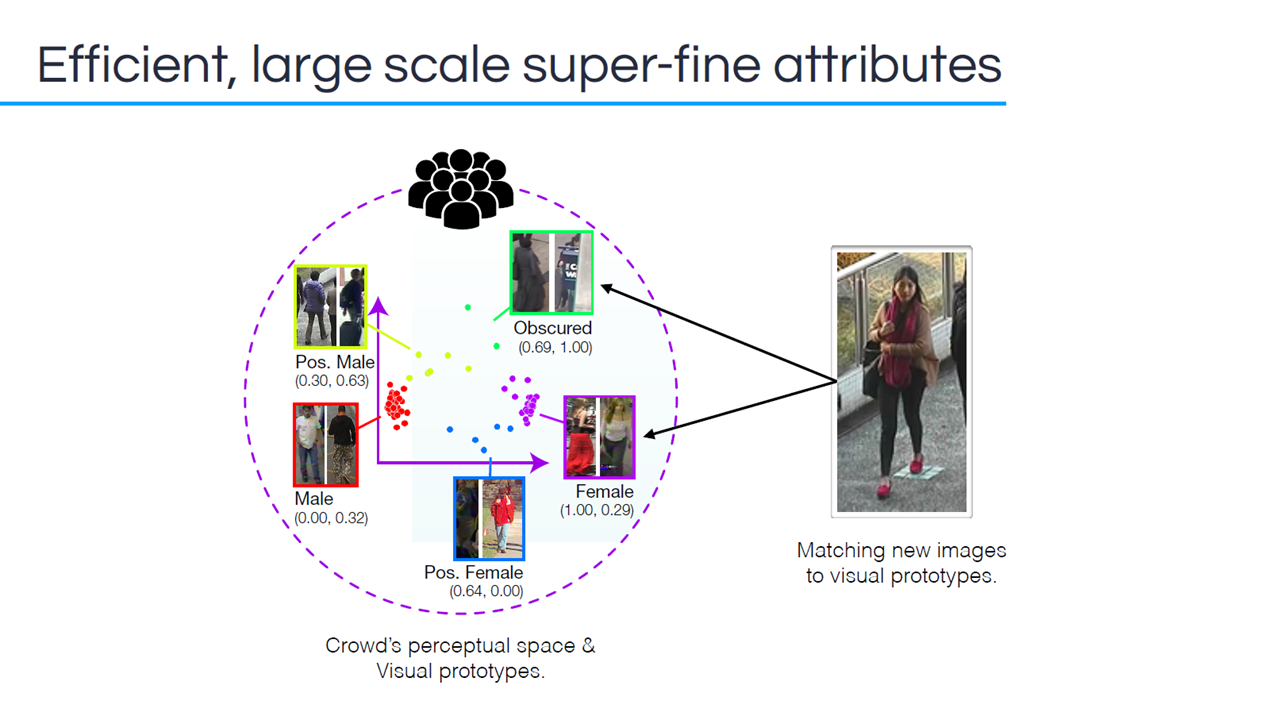 Matching new images (Image credit)
Matching new images (Image credit)“We just match the new image to whichever prototype it’s most related to. This is a more objective way for humans to label new images.” —Dr. Daniel Martinho-Corbishley
Yet, another scenario may imply super-fine age labels applied for image classification. This way, the division between ages is clearly depicted with “very young” and “very old” at opposite corners of the data set.
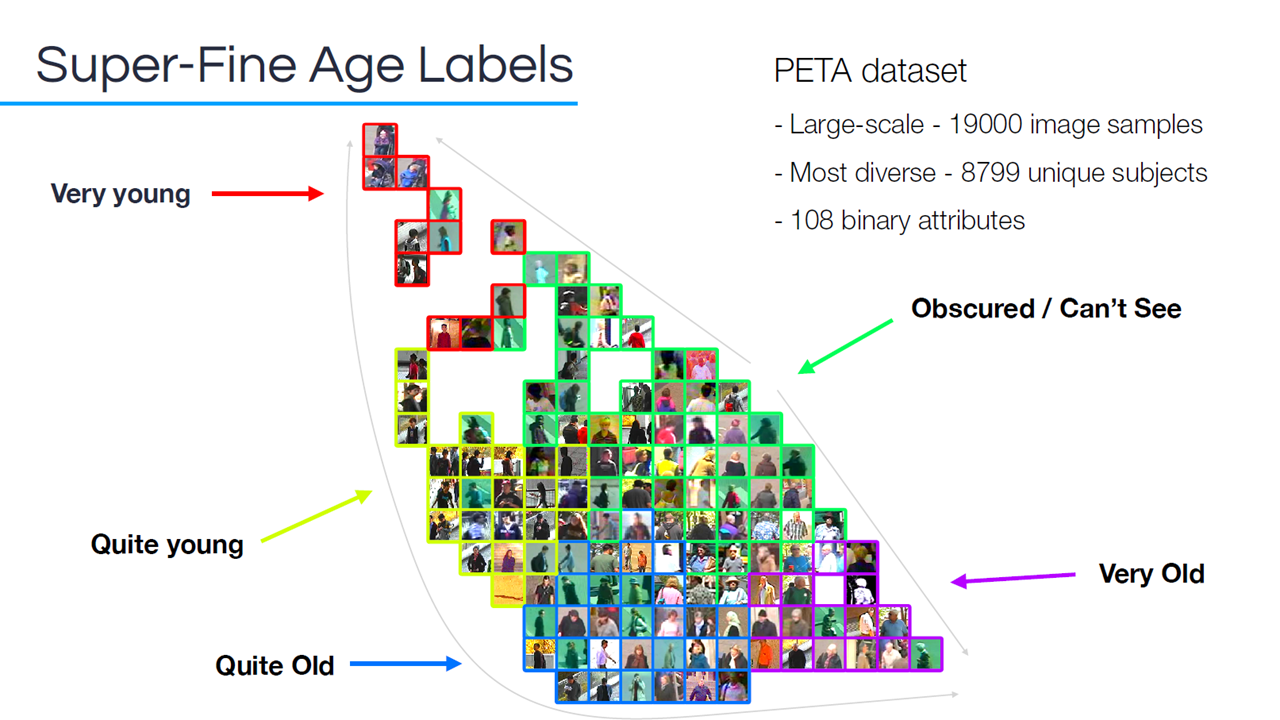 Super-fine age labels created from the pedestrian attribute (PETA) data set (Image credit)
Super-fine age labels created from the pedestrian attribute (PETA) data set (Image credit)“Age is really interesting. We get very young at the top left, and then we get this gradient of age through the space as they get older and older. This is exactly what we’d expect, because very young and very old are visually the most distinct classes, so you can see that there’s a large distance between them. As they become obscure, they cluster in the middle, because you can’t tell anything about the age.” —Dr. Daniel Martinho-Corbishley, Aura Vision Labs
Accelerating a super-fine model with TensorFlow
During the presentation, Daniel shared a few TensorFlow techniques, which, according to him, “helped to iterate solutions faster.” In particular, his team made use of the tf.train.slice_input_producer function to shuffle and slice tensors, read images, and batch inputs.
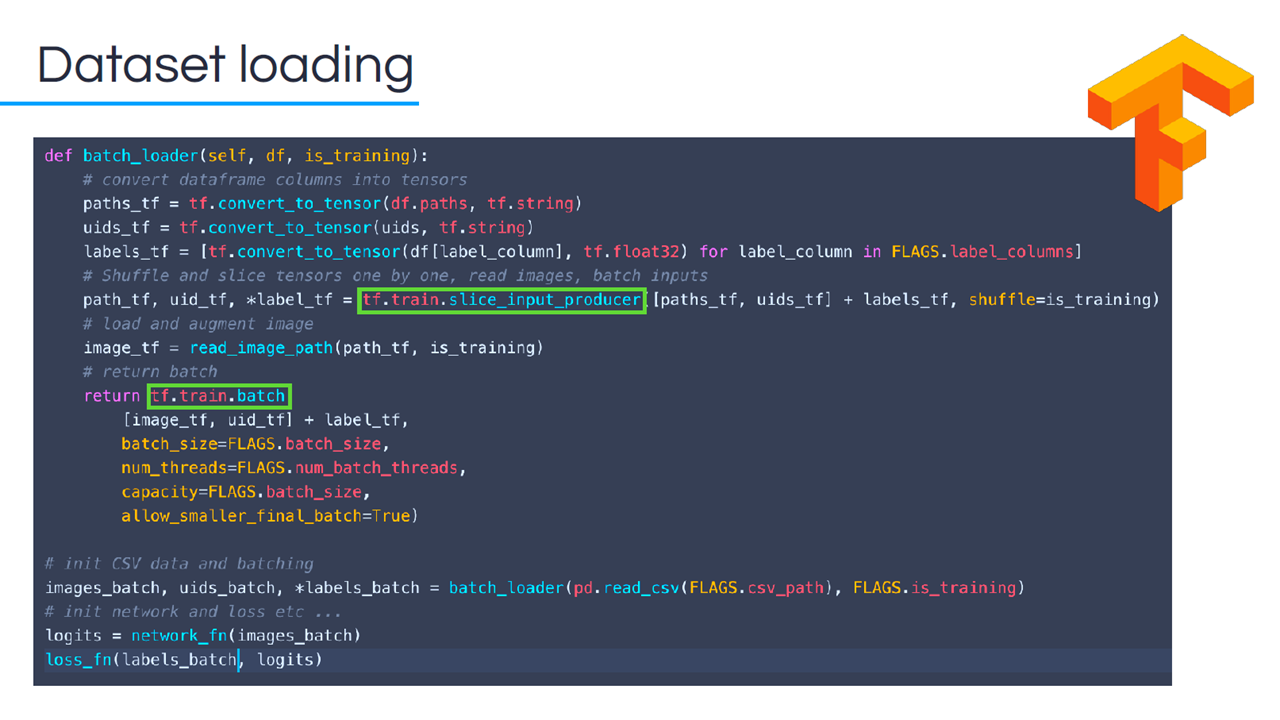 Data set loading with TensorFlow (Image credit)
Data set loading with TensorFlow (Image credit)“TensorFlow is very flexible, you can add another tensor if you want to have some metadata that’s working alongside your training data and it’s not so much to fiddle with.”
—Dr. Daniel Martinho-Corbishley, Aura Vision Labs
To increase the variance and improve the robustness of the model, the read_image_path function may be created. It allows for augmenting images in various ways, such as flip, color, rotate, and stretch.
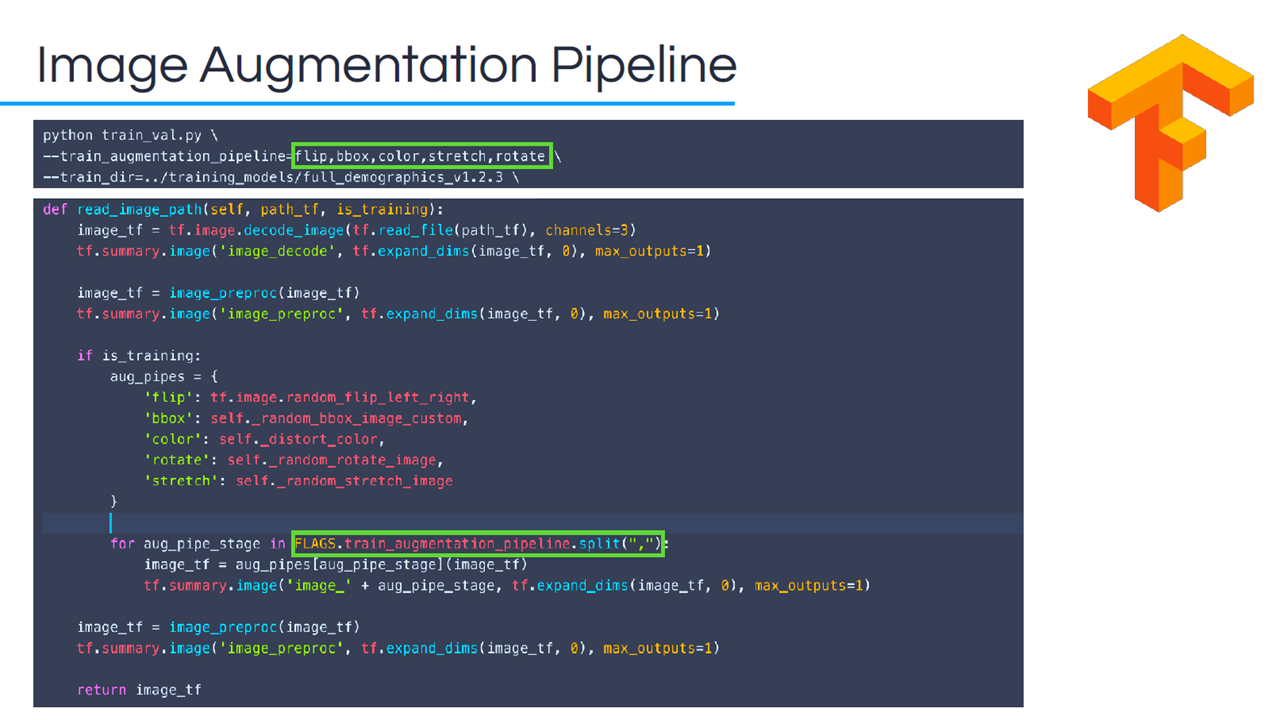 Image augmentation with TensorFlow (Image credit)
Image augmentation with TensorFlow (Image credit)TensorFlow also enables the training of multiple models on different data sets.
 Training multiple models with TensorFlow (Image credit)
Training multiple models with TensorFlow (Image credit)“You’ve got variable scoping, so you simply initialize the network. You have different variable scopes for different stages of the model. We then train those models separately. When we want to load in those check points, we just create a saver.” —Dr. Daniel Martinho-Corbishley
To get a comparison between image classification types, Daniel and his team trained a ResNet-152 model with binary classification and super-fine regression.
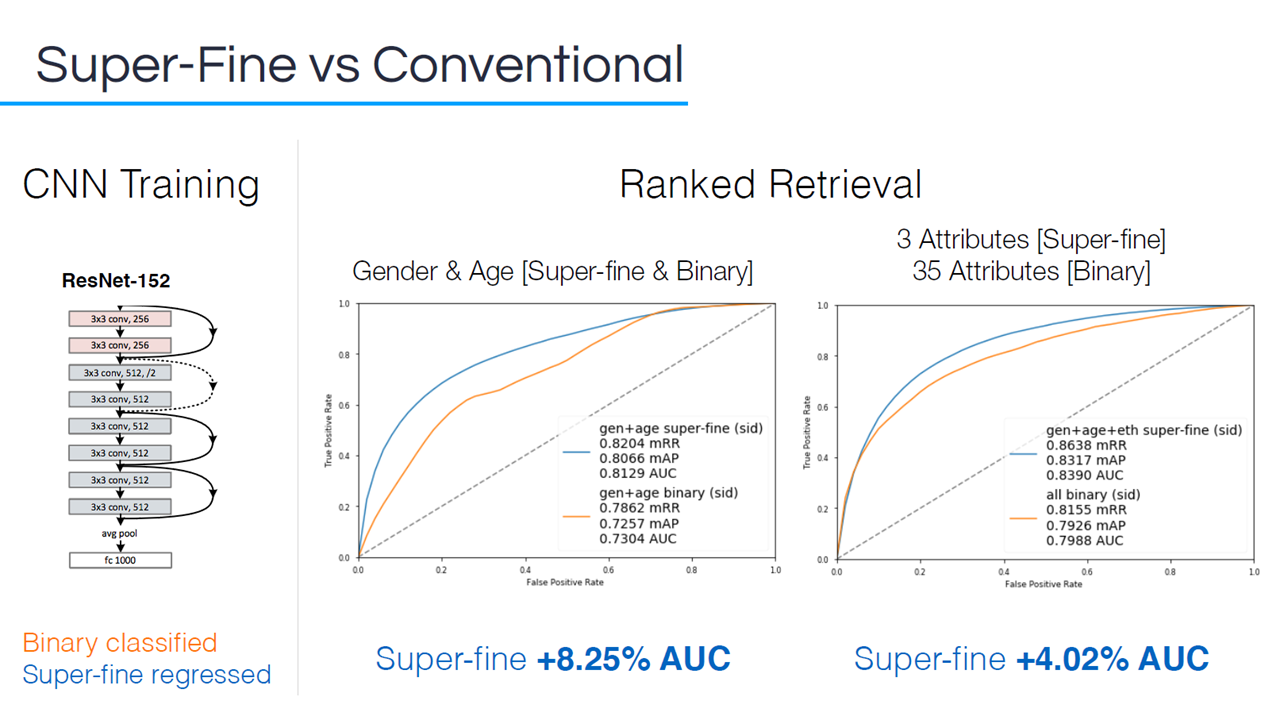 Super-fine and binary model comparison (Image credit)
Super-fine and binary model comparison (Image credit)“For just gender and age attributes, we see super-fine outperform binary by 8.25% on the area under curve. When we have three super-fine attributes, and we compare that to 35 binary attributes, we see that super-fine still outperforms by 4%. That’s because the labels are much more discriminative, more objective, so the labels are much more relevant for those images. The machine is able to learn a better representation for each image.”
—Dr. Daniel Martinho-Corbishley, Aura Vision Labs
Who can use this?
So, what can the super-fine model offer to the real world? According to Daniel, it works well in the retail analytics space. Through the super-fine model, retailers can get a better grasp of market demographics.
“If a store is running a marketing campaign to target females aged 25–34, they need to know if it is actually working. Before they would have a footfall counter say a few more people walked into the store, but did it actually work? Now, you can actually tell them how many of that demographic they were targeting came to their store.”
—Dr. Daniel Martinho-Corbishley, Aura Vision Labs
 Aura Vision Lab’s super-fine recognition (Image credit)
Aura Vision Lab’s super-fine recognition (Image credit)Though the scenario Daniel exemplified was for commercial retail purposes, the flexibility in the super-fine model can be adopted to fit other requirements. Organizations that rely on hard biometrics can fallback on soft biometrics and super-fine attributes to create recognition software that is just as reliable, if not more so.
Want details? Watch the videos!
Table of contents
|
Below are Daniel’s slides during the meetup.
Further reading
- Using Machine Learning and TensorFlow to Recognize Traffic Signs
- Analyzing Satellite Imagery with TensorFlow to Automate Insurance Underwriting
- Using Long Short-Term Memory Networks and TensorFlow for Image Captioning
About the expert