Hadoop + GPU: Boost Performance of Your Big Data Project by 50x–200x?

Learn about possible bottlenecks when offloading Hadoop calculations from a CPU to a GPU and what libraries/frameworks to use.
Accelerate your project
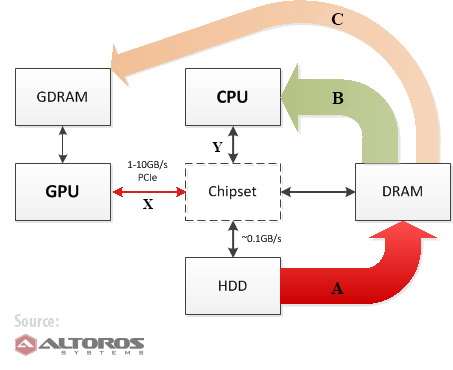
Hadoop, an open-source framework that enables distributed computing, has changed the way we deal with big data. Parallel processing with this set of tools can improve performance several times over. The question is, can we make it work even faster? What about offloading calculations from a CPU to a graphics processing unit (GPU) designed to perform complex 3D and mathematical tasks? In theory, if the process is optimized for parallel computing, a GPU could perform calculations 50–100 times faster than a CPU.
Read this article at NetworkWorld to find out what is possible, and how you can try this for your large-scale system.
Check out this white paper to explore the idea in detail.
Further reading
- Hadoop + GPU: Boost Performance of Your Big Data Project by 50x-200x?
- Hadoop Distributions: Cloudera vs. Hortonworks vs. MapR
- Processing 5 TB of Data Daily with Hadoop and Cassandra

Posted In