Reducing ETL and Data Integration Costs by 80% with Open Source

Millions of dollars spent on ETL
Companies of all sizes are challenged to deliver their products and services to market faster and to manage more complex sales and marketing programs with limited budgets and decreasing time frames in order to accelerate revenue generation. To do so, having the right data integration and data quality model is critical.
Today, companies spend enough on data Extraction, Transforming, and Loading (ETL) to start questioning whether this technology is as beneficial as it is positioned; and the costs associated with it are still going up. Yet, most companies seem to underestimate their own expenses on ETL. License costs are the only factor (albeit not an inexpensive one, for sure) to be typically taken into account, while the real Total Cost of Ownership (TCO) is comprised of labor costs and hardware costs as well, and can outnumber license costs by many times.
According to Gartner, corporate developers spend approximately 65 percent of their effort building bridges between applications.
The true amount that an enterprise may spend on ETL can reach millions of dollars. Non-IT executives would be horrified to realize how enormously money-consuming data integration is. But, there is a way out.
This article will show how saving up to 80% on ETL costs is possible with open-source technologies. We will analyze the Total Cost of Ownership of a typical data integration project, break down the cost structure, determine how each of the costs can be cut down, and then offer examples of major companies that have saved on data integration.
Why is data integration so expensive?
In 2003, the total spending by enterprises worldwide on data integration was about $9.3 billion. In 2008, it is expected by IDC to comprise more than $13.5 billion. The reality is that data integration projects are becoming more complex, the amounts of data are expanding, and the cost of taking good care of data is becoming more and more expensive. Under tough economic conditions, for many companies the total cost of ownership for the enterprise of proprietary data integration solutions is becoming prohibitive.
And the issue is not only about the license costs. According to Yankee Research, over a three-year period, the TCO of an integration application is more than eight times the initial software license investment. So in fact, it’s the running cost that is the most expensive. Comprised of the yearly license fee, hardware costs, and labor costs, the real TCO of a data integration solution, according to Yankee Research, can rise up to $509,600 annually—and the number seems to be increasing with every year.
One may start to think of data integration as something that constantly consumes enormous resources, human and financial, but that is only half the story. The other half is that to reduce the TCO you have to change the cost structure, that’s it.
Today, you can save on most items in a “data integration shopping cart,” starting with the license fees. There are a number of open-source solutions available for evaluation and real-world projects at no charge. With open source, you can practically eliminate licensing fees altogether.
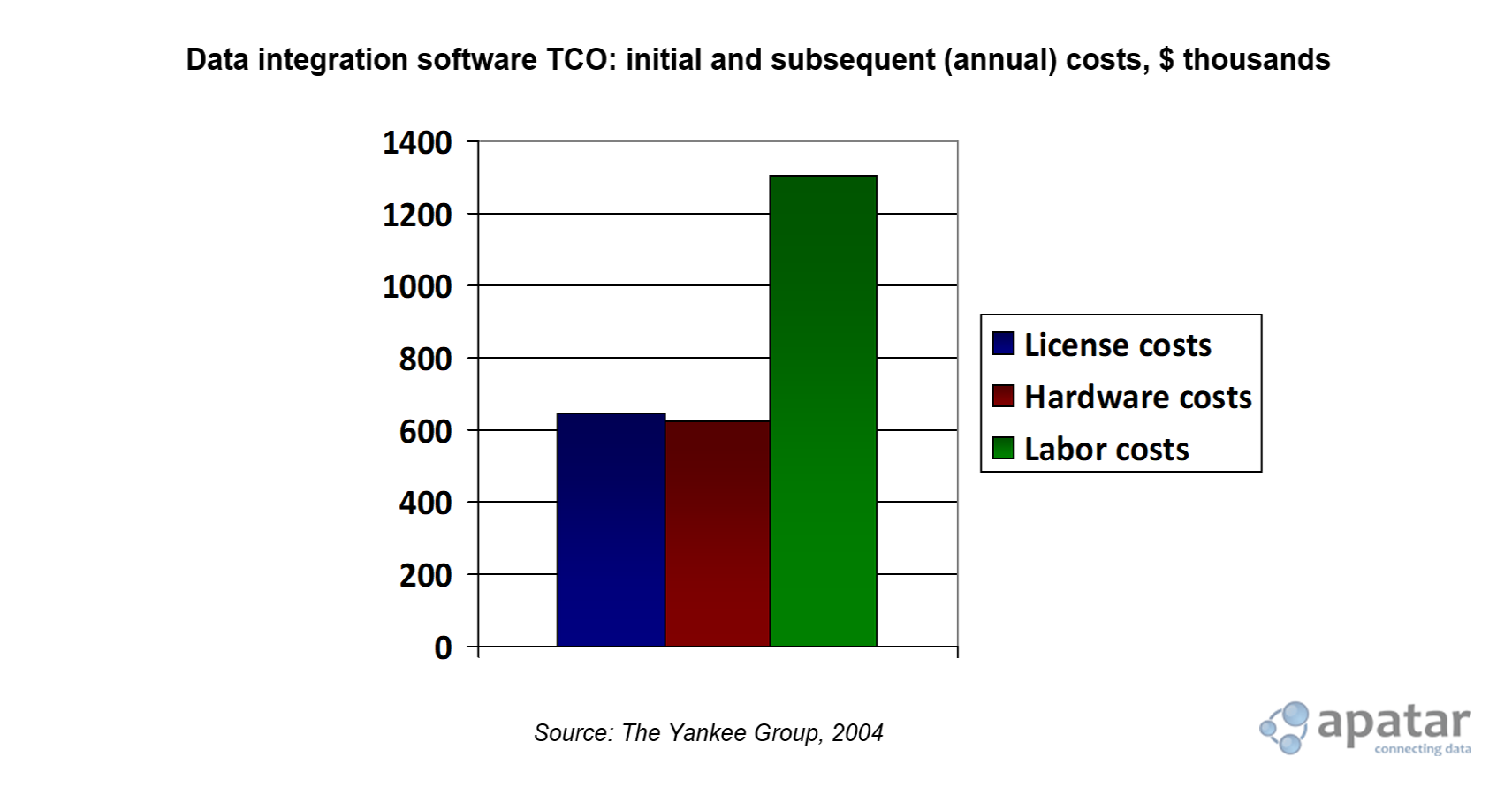 Data integration software TCO
Data integration software TCOAs far as hardware costs are concerned, solutions that require their own servers and/or mainframes seem to be unreasonably expensive to implement. While the hardware costs of implementing such solutions are on average about $300,000, the hardware costs of products, which can run on existing servers and desktops drop down drastically, to a mere $10,000 in some cases. So, eliminating the vendors whose solutions do not provide an acceptable level of openness can result in a considerable savings.
When it comes to labor costs, there are two main criteria:
- The first one is whether the solution is straightforward enough for a non-trained user to understand, and whether it is effective, which means that the user is able to do the job in minimal time.
- The second criterion is the flexibility of the product, the extent of reusability of its configuration for subsequent tasks.
Usually, open source can provide both, targeted at and supported by a large community that aims to consistently enhance the development. On the other hand, when choosing a proprietary solution, it is important to keep in mind that while many companies tend to underestimate TCO, for every dollar spent on data integration software, enterprises spend $6 more on subsequent implementation and support.
Enterprises go open source
Thousands of companies worldwide entrust their enterprises to open-source solutions such as Linux and MySQL, including such industry leaders as Yahoo!, Google, Cisco, Panasonic, Alcatel-Lucent, Nokia, Associated Press, and many others. Just ten years ago, using open source might have seemed inappropriate for a big company’s ideology. Now that the benefits of freely distributed software have become more evident than ever and an abundance of such products have appeared in the market, more and more companies are going open source.
“Over the past few years, open source has become the technology we consider when there’s something we need,” says Jeremy Zawodny, a member of Yahoo!’s technology development team. “When I joined Yahoo!, the data-management part of that system was crude and written internally, and one of the first things I did was replace that with MySQL,” Zawodny says.
 Open-source benefits
Open-source benefitsOpen-source data integration is no exception. Freely available solutions are doubly beneficial, bringing the license cost down to the minimum and enabling companies to save dramatic amounts on maintenance. This is why organizations such as Continental Airlines, NASA, AXA, Fidelity, etc. rely on open source when it comes to integrating their data. But is it all only about money?
In truth, open source is not only good in terms of saving money. It also has a number of further advantages over traditional software:
- Better performance and reliability. Open-source solutions have vast communities of developers, which ensure testing of all the functional range of a product on different platforms before release. It also guarantees that bugs are found and fixed rapidly. The required enhancements to the code are also easier to make due to the number of developers and the availability of the source code.
- Available for many platforms. Typically, open-source software supports numerous platforms, leaving it to the user to choose the one that fits his or her requirements better. Somehow, this freedom of platform choice seems to be something many proprietary software solutions cannot offer.
- Higher level of security. With the source code publicly available, open-source software typically suffers fewer vulnerability attacks than proprietary solutions. And as soon as a vulnerability is revealed, it is instantly addressed to the developers who fix the problem promptly.
- Flexible. Highly tailored open-source solutions are a very rare thing to see. Most open-source developments allow a tremendous scale of flexibility and can be reused in a vast range of cases with little to no customizing required. With open source, you do not have to use multiple solutions to integrate data from Salesforce CRM to a MySQL database or from GoldMine to SugarCRM.
- Easier to deploy. There is a tendency for open-source software to concentrate on the essential features instead of implementing dozens of secondary features that hardly anyone uses. Due to that, such software is usually more straightforward to use than proprietary products. Moreover, with the huge communities open-source developments have, help on any feature of the product can be found in a matter of hours.
- Safety from vendor lock-in. When using traditional software, one is greatly dependent on the vendor. To a degree, this could be regarded as one of the reasons that data integration is getting more expensive nowadays. Entrusting data to a vendor is very dangerous, as moving it to a different vendor afterwards is such a hassle that it is often considered less resource-consuming to accept whatever conditions the current vendor lays down. Even if these conditions are different from what one expected when one signed on. Open source is without a doubt the most reliable option in this respect. With the solution distributed freely and the source code out in the open, lock-in is absolutely ruled out.
Major companies recognize lower TCO
It certainly looks as if the tendency of major companies to switch over to open source is not just to stay, but is a turning into a quiet revolution in the software market. The practical benefits of using open source often exceed expectations. And as many enterprises have already verified that for themselves, even more companies are following in their steps.
Financially, for any open-source convert, the advantages of going open source over staying with proprietary software are irrefutable.
NASA’s Acquisition Internet Service (NAIS), which has grown vital to the agency’s business, is managing large acquisitions online with the world’s most popular open-source database MySQL.
NASA’s Acquisition Internet Service saves over $4 million per year with open source.
When their previous database vendor decided to restructure its license program, NASA was faced with fees that would cost more than twice their total annual budget for a simple upgrade, according to Dwight Clark, NASA Systems Analyst. Switching to MySQL helped NASA resolve the issue, saving over $4 million per year. Furthermore, using MySQL turned out to be beneficial in a number of unexpected ways, providing better reliability, productivity, and slashed support costs.
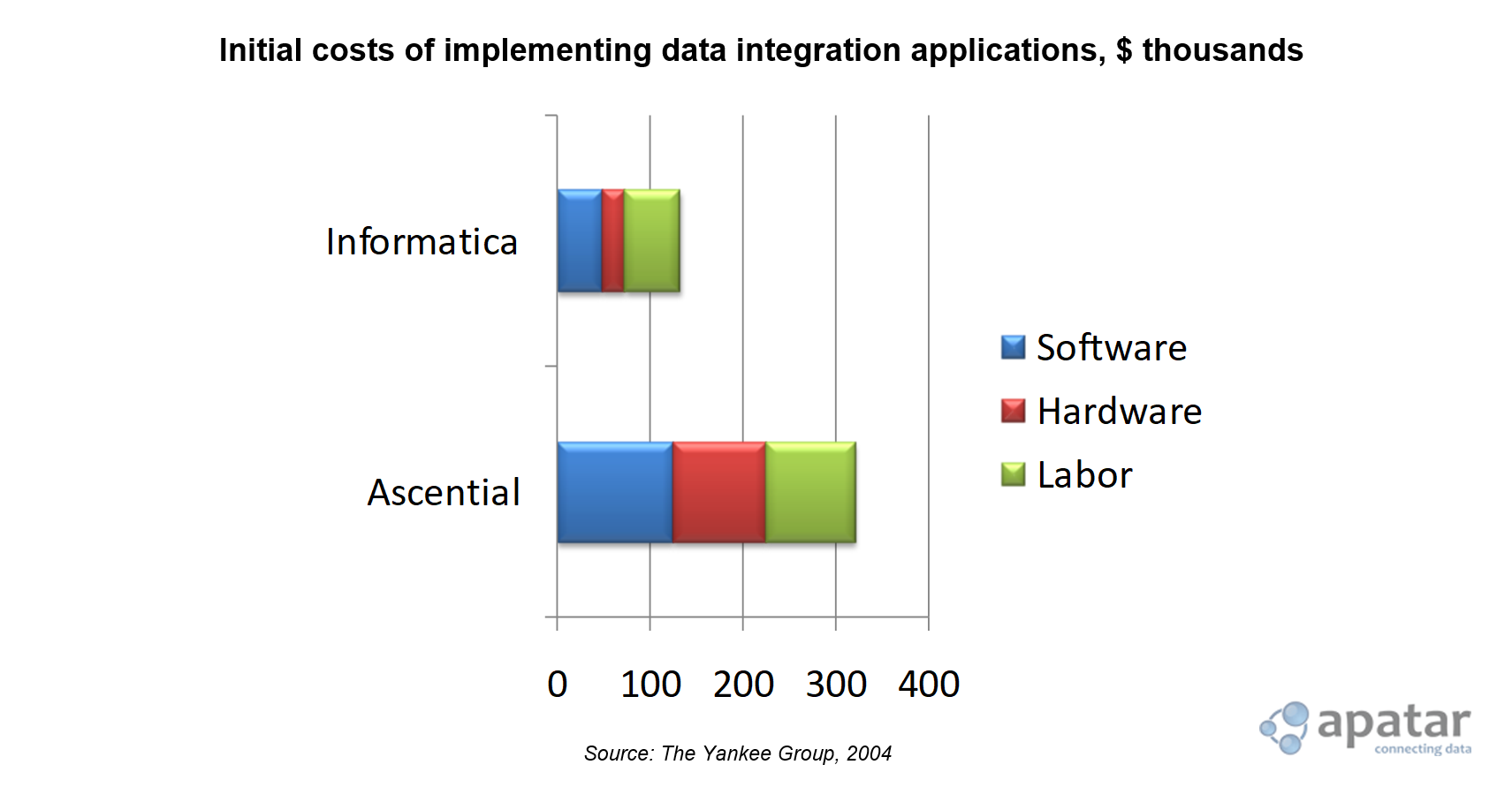 Initial costs of implementing data integration applications
Initial costs of implementing data integration applicationsThe ultimate open-source office application suite OpenOffice.org is used by 14% of large enterprises worldwide, including the French Gendarmerie, Bristol City Council, and Singapore’s Ministry of Defense. General Brachet, the French gendarmerie’s head of IT, says using open-source products helps the police save millions of Euros per year.
According to Netcraft, the open-source project, Apache has been the #1 HTTP server on the Internet for more than 12 years now, and it is recognized as such by Hewlett-Packard, Adobe, and Apple, to name just a few. This has to be because of the extreme economy it provides, as, according to research conducted by TechRepublic, enterprises can save about 60%–90% with Apache, depending on which of the popular proprietary competitors it is compared with.
Measuring TCO benefits of open-source data integration
Open-source ETL and data integration solutions can save money in a number of areas. The key areas of economy open source provides are:
- License costs. Even though today’s proprietary data integration software market involves great competition, the license costs of different vendors’ products remain very different. The license costs of solutions provided by some of the major vendors can be a substantial expense item for an enterprise, sometimes exceeding $500,000 annually. Reducing the license cost by going open source enables an enterprise to use the released budget for other business tasks.
- Lower operation and support costs. Many open-source solutions are notably easier to use than proprietary tools. But even more importantly, thanks to so many people participating, the open-source products are in most cases extensively documented. The thorough documentation they provide ensures mastering the product quickly and without unnecessary effort. On top of that, the huge developer and user communities make it possible to receive support from other users, without paying for it. With such communities, one can get any possible question quickly answered, which guarantees minimum time and money loss due to downtime.
- Ready customization schemes available from communities. Another benefit the open-source product communities give is the large number of ready-to-go customization schemes developed by their members and often available for free. So after installing the application, you might not even need to spend your time setting it up for your specific situation, you can just use the scheme created by someone who has been in the same shoes before you. Proprietary software quite often allows creating reusable schemes too, but it is rather seldom for the vendors to encourage free sharing of those. By choosing open source, you can save on labor time greatly, relieving the user of the necessity to do everything manually.
Apatar open-source data integration
One of the open-source tools that can help to cut down data integration costs is Apatar, an open-source ETL project. A response to the overwhelming demand by the companies dealing with business information scattered across distinct applications, Apatar is distributed under open-source GNU General Public License (GPL 2.0).
Apatar was designed to help developers and business users move data in and out of a variety of data sources and formats. Remarkably flexible, as an ideal ETL solution should be, it provides connectivity to MySQL, Salesforce.com, GoldMine, Oracle, Flickr, Amazon S3, SugarCRM, XML, RSS, CSV, Microsoft Excel, Microsoft SQL, FTP, POP3, WebDav, Autodesk Buzzsaw, any JDBC data sources, and more.
100% Java-based, Apatar is platform-independent and runs on Windows, Linux, and Mac OS. With the source code included, the solution is easily customizable.
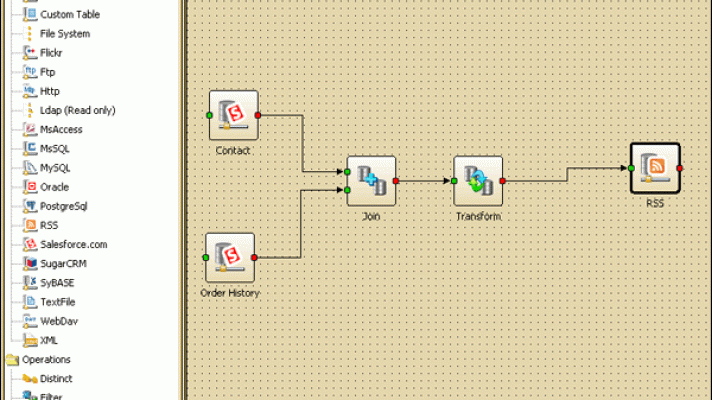
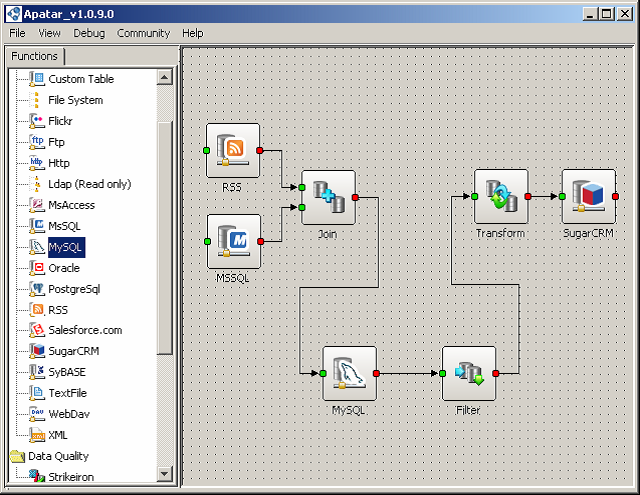 Apatar’s visual work panel
Apatar’s visual work panelMaking it possible to accomplish integration of virtually all levels of complexity, Apatar requires no coding skills. Users can drag-and-drop data between databases and applications using a visual mapping interface. This helps to save time and effort, which results in lower labor costs.
Data-integration jobs created with Apatar (called DataMaps) can be stored on your local drive, which makes subsequent reuse possible. Saved DataMaps can be shared via Apatarforge.org, Apatar DataMap Repository, hosting hundreds of ready-to-go DataMaps for a variety of situations. Before creating their own DataMap, you might want to check if there is a ready one at the DataMap Repository, since one of 5,000+ Apatar users could have encountered the same task as you and posted up a solution.
Apatar Scheduler, which can schedule DataMaps to start automatically, allows running recurring jobs without employing any labor resources.
Not only does Apatar integrate data, it also helps improve its quality. By means of such integrated data verification services as StrikeIron US Address Verification, StrikeIron Email Verification, CDYNE Death Index, and others, Apatar can automatically filter outdated and invalid data.
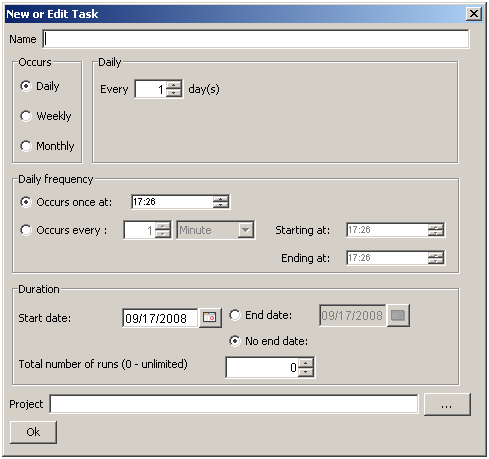 Apatar Scheduler setup
Apatar Scheduler setupLarge financial services company Credit Suisse Group, major software vendor Autodesk, the world’s largest international insurance and financial services organization Allianz, major industry player in telecommunications Alcatel-Lucent, and the Fortune 500 company R.R. Donnelley have at least one thing in common: they rely on Apatar, alongside many more users.
“I was impressed by how easy it is to use this tool and to obtain results quickly. The lack of knowledge on how to perform some specific functions was rapidly solved within the forum.” —Fabio Pifferini, Internal SAP Consultant
Best practices
Below, you can find some useful tips to consider when choosing an open-source product.
- Go open source. The truth is that most data integration projects in today’s enterprises never get built. The ROI (Return on Investment) on these small projects is simply too low to justify bringing in expensive middleware. That’s why you may consider using commercially supported open-source tools for your integration projects. You may want to consider Apatar’s application to design and orchestrate data integration processes, as well as MySQL database to host data warehouse and staging tables.
- Read the license. Take the time to clarify conditions of use and make sure that what you are dealing with actually is open source, and the terms of use suit you well. Different licenses can have very different consequences. Besides, not every freely distributed product is open source. Be aware there can be pitfalls.
- Remember the source code. One of the huge advantages of open source over proprietary software is the openness of the source code. Keep in mind that you are always free to view, fix, and modify it.
- Make sure to use version 1.0 or later. It is not rare for open-source software to be released while on rather early stages of development. Therefore, version numbers like 0.2.5 or 0.7.1.2 are no rarity either. Although these versions actually can be very stable and mature, it is generally believed that a product has to reach version 1.0 to be considered for enterprise use.
- Check the latest version’s release date. It is clear that not all open-source solutions work out. Sometimes they do for the users, but not the developers. If you want the product to be regularly updated with new features and bug fixes, you have to make sure that you are dealing with an active developer. Check the release date of the latest version of the product. If it’s been a while, probably you should reconsider your choice.
- Opt for flexibility. While most open-source products are rather flexible in their capabilities, there are a number of very narrow solutions, which are applicable for just one particular situation. It’s certainly up to you to decide whether such products suit you, but bear in mind that your specific needs might change slightly, and if your solution fails to match them anymore, it will take time and resources to move to a different platform.
- Ponder over the real economy. Remember that license costs are not your only expense when implementing software. If an open-source product is difficult to learn to use or implement, think again whether it is actually worth it.
This way, by using open-source technologies, companies can save a significant amount of their data integration budgets. Still, by following these recommendations, one can make sure that the ETL processes stay as mature as with proprietary DI tools.
Appendix: References
- Uncovering the Hidden Costs in Data Integration. (Yankee Group)
- Steve McClure. Market Analysis. Worldwide Data Integration Forecast: 2004-2008. (IDC)
- The Future of Data Integration Technologies. (META Group)
- Rick Banister. Choosing an ETL Technology. (Sesame software)
- Wayne Eckerson, Colin White. Evaluating ETL and Data Integration Platforms. (TDWI)
- Philip Russom. How to Evaluate Enterprise ETL. (Forrester)
- Colleen Graham, Nicole Latimer, Fabrizio Biscotti, Joanne Correia, Chad Eschinger, Chris Pang, Thomas Topolinski. Enterprise Software Industry Analysis. Software Market Research, Methodology and Definitions, 2003-2004 (Forrester)
- Jason “Hiner MCSE, CCNA”. Evaluating TCO for iPlanet, Apache, and IIS. (TechRepublic.com)
- Larry Greenemeier. Open Source Goes Corporate. InformationWeek, September 26, 2005.
- Sean Michael Kerner. Open Source ETL Takes On Proprietary Intelligence. Internetnews.com, July 25, 2007.
- Randy Metcalfe. Top Tips for Selecting Open-Source Software. OSS Watch, February 2004.
- Dennis Kennedy. Best Legal Practices for Open-Source Software: Ten Tips For Managing Legal Risks for Businesses Using Open-Source Software. Llrx.com, February 7, 2006.
Further reading
- What Is Apatar Open Source Data Integration?
- ETL vs. ESB from Apatar’s Point of View
- Top Data Integration Challenges: Meet DQ, CDI, EAI, DW, and BI