
GitHub Crafts 10+ Custom Kubernetes Controllers to Refine Provisioning

Controllers extend toolchain functionality
In DevOps, toolchains are used to help to orchestrate the delivery, development, and management of applications throughout the development life cycle. Tools like Ansible and Terraform can be grouped together to create a toolchain. Toolchains can then consecutively run the linked software in such a way that the output of each becomes the input for the next one.
While toolchains are useful, sometimes they are unable to fit developer’s exact requirements. A toolchain may also get to a point where several solutions get added over time requiring developers to be familiar with every single piece of software that’s in use.
These were some of the problems GitHub stumbled upon during their adoption of Kubernetes three years ago. At a meetup in Dallas, Ross Edman of GitHub alluded to such toolchain limitations and exemplified how controllers in Kubernetes can save the day through their functionality.

Ross Edman
“Toolchains only go so far. At some point, no matter how many toolchains you string together, you’re not going to get exactly what you want for your business. If you’ve been in operations a long time, you’ve experienced toolchain explosion where you have to know Chef, Puppet, Ansible, Terraform, and it just goes on forever. At some point, you can’t get all that stuff to build exactly what you want.” —Ross Edman, GitHub
Controllers are basically endless loops that regulate the state of any system. Given a desired state, a controller will facilitate the necessary processes to get the system to the desired state.
As an example, a heating, ventilating, and air conditioning (HVAC) system in a home can be thought of as an endless loop. In this scenario, a user can define a desired state by setting the temperature. As a controller, a thermostat then communicates with a heater, a ventilator, and an air conditioner until the set temperature is met.
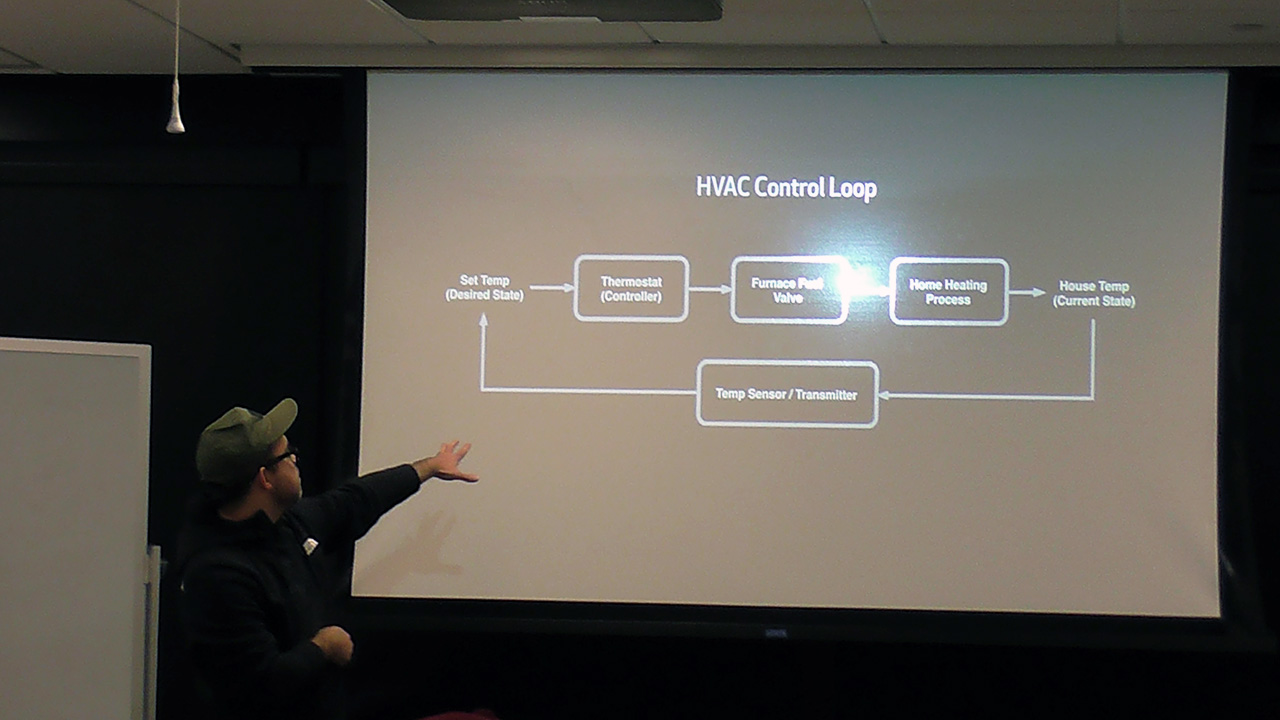 The thermometer is the controller in an HVAC system
The thermometer is the controller in an HVAC systemSimilarly, in Kubernetes, controllers are control loops that monitor the shared state of a cluster through an API server and make adjustments to move the current state towards the desired one. Some of the existing controllers in Kubernetes include:
- A node controller is responsible for noticing and responding when nodes go offline.
- A deployment controller maintains ReplicaSets.
- A replication controller manages the correct number of pods for every replication controller object in the system.
- An endpoints controller administers the network topology between services and pods.
- A volume controller takes care of creating, attaching, and mounting volumes, as well as interacting with the cloud provider to orchestrate volumes.
“Controllers are the magic that we all think of when we see Kubernetes.” —Ross Edman, GitHub
Custom controllers built by GitHub
According to Ross, there are over 10 custom controllers which help GitHub to run. So, he highlighted some of them:
- A namespace bootstrapping controller provisions images, metadata, resource quotas, and limit ranges when a namespace is created.
- A deployment orchestration controller monitors deployments across clusters, injects annotations, and reports back the status.
- A node problem correction controller watches the state of nodes and attempts to fix erroneous nodes by cordoning them off, draining workloads, restarting them, and applying healing procedures.
“We use controllers for a lot of stuff. Right now, 100% of GitHub.com runs on Kubernetes and we orchestrate all of that with custom controllers.” —Ross Edman, GitHub
 Ross Edman at the meetup in Dallas
Ross Edman at the meetup in DallasCustom controllers are made possible by extensive the API of Kubernetes, which enables developers to do away with toolchains. During his presentation, Ross demonstrated how to build custom controllers.
“All the things you use in Kubernetes, you can change and affect at every different level. You can do this in a way where you’re not composing all these toolchains to do it. You can do it in a couple hundred lines of code and it can make a huge difference to your business.” —Ross Edman, GitHub
Kubernetes on bare metal at GitHub
While controllers now play a vital role in GitHub, it is only a small portion of how the company’s infrastructure utilizes Kubernetes.
According to Jesse Newland of GitHub, before adopting Kubernetes, the company’s site reliability engineers (SRE) were overloaded with server maintenance and provisioning. As the community grew, so too did the burden on the SRE team. New services took days, weeks, or months to deploy depending on complexity and the SRE team’s availability.
At the evaluating stage in August 2016, the team of GitHub experimented with deploying a small cluster and an application on Kubernetes in just a few hours, and it was the result, which greatly favored the choice of Kubernetes that followed.
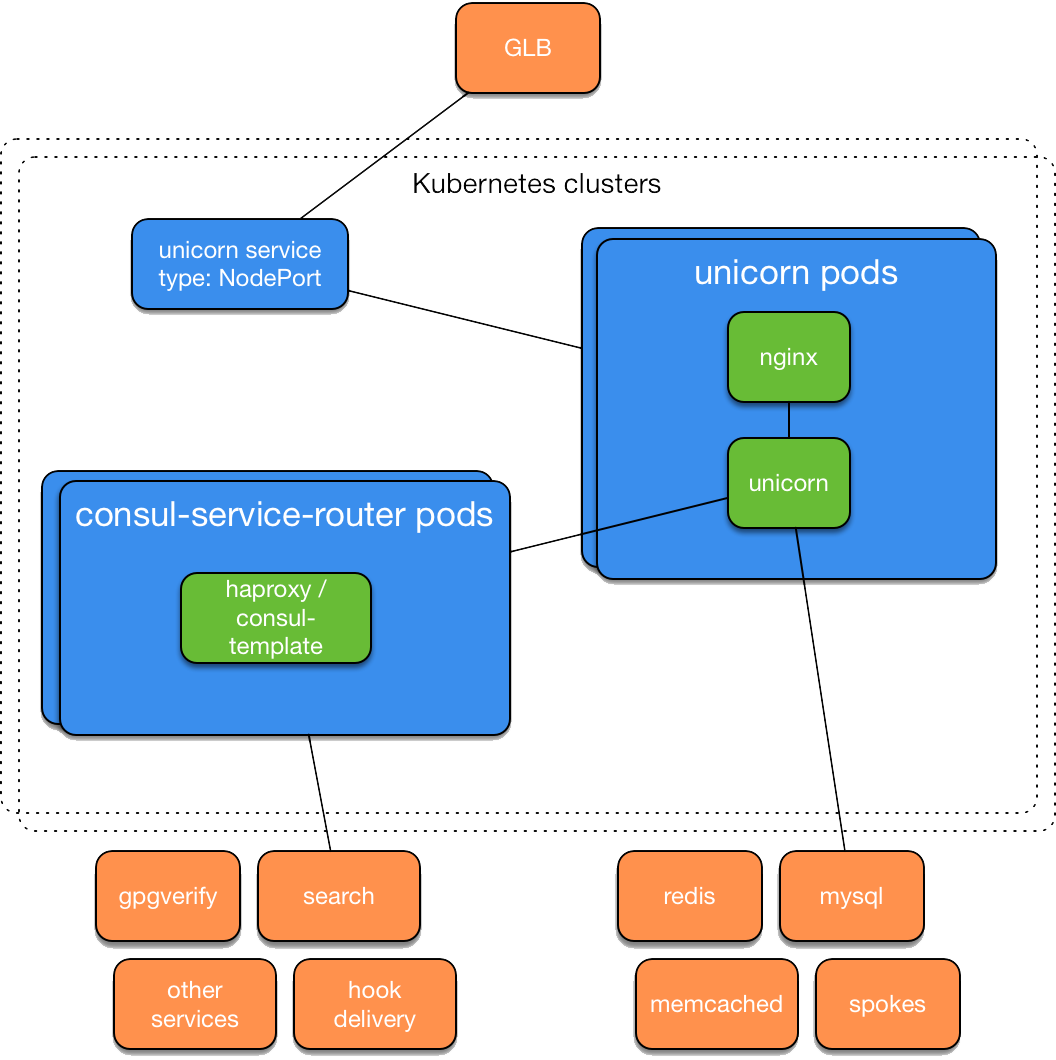 GitHub on Kubernetes (Image credit)
GitHub on Kubernetes (Image credit)The company decided to stick to an achievement-oriented approach and experiment further rather than setting up a particular deadline for full migration to Kubernetes. So, the next step to take was building a “review lab”—a deployment environment driven by Kubernetes to support exploratory testing of the combination of the container orchestrator and the services that would run on it. This “review lab” project is similar to the already existing GitHub environment called “branch lab.”
The rest of 2016 was dedicated to this, and quite an impressive number of sub-projects were delivered in the process, including:
- a Kubernetes cluster running in an AWS Virtual Private Cloud and managed using a combination of Terraform and kops
- a Dockerfile for github.com and api.github.com
- YAML representations of 50+ Kubernetes resources
- a set of Bash integration tests exercising ephemeral Kubernetes clusters
The experimenting resulted in a chat-based interface for creating an isolated deployment of GitHub for any pull request.
While building its Kubernetes cluster, GitHub also achieved the following:
- Utilized Calico, which provided out-of-the-box functionality necessary for shipping clusters in IP-in-IP mode
- Built a tool to generate the certificate authority and configuration needed for each cluster
- Puppetized the configuration of two instance roles—Kubernetes nodes and Kubernetes API servers
- Delivered a Go-based service to process container logs and send them to the hosts’ local Syslog endpoint
- Enhanced GitHub’s internal load balancing service to support Kubernetes NodePort Services

Jesse Newland
Additionally, after successfully running a Kubernetes cluster in an AWS, the GitHub team was able to migrate the entire workload to the company’s bare-metal cloud in less than a week. Overall, the transition from internal to external Kubernetes lasted about a month.
At the moment, the Kubernetes cluster of GitHub already has dozens of applications deployed to it. Each of these applications would have previously required configuration management and provisioning support from the SRE team. With the move to Kubernetes, GitHub now has a self-service platform that can deploy and scale new services. Additionally, modifying and provisioning resources on Kubernetes can be done in seconds.
“I can already see how the move to Kubernetes is creating an environment at GitHub for more rapid innovation—innovation that will benefit users and, ultimately, the software industry as a whole.” —Jesse Newland, GitHub
This initial tryout of Kubernetes was limited only to stateless workloads, so now the team at GitHub is planning to further experiment with running stateful services on Kubernetes.
Want details? Watch the video!
Further reading
- Enabling High Availability and Disaster Recovery in Kubernetes
- NetApp Builds Up a Multi-Cloud Kubernetes-as-a-Service Platform
- Kubernetes Cluster Ops: Options for Configuration Management
About the experts






