
Enabling Persistent Storage for Docker and Kubernetes on Oracle Cloud

The need for persistent storage
The very essence of immutability implies that once a container image is created, it cannot be altered. If you need to change any bit of data, you have to recreate a container and then kill the one storing the outdated information.
Here comes the challenge of maintaining persistence for the containerized apps. The app data maps to the containers, which are immutable, while the data is constantly changing. And this, in its turn, contradicts with the nature of immutability. So, the question is, how to address this contradiction?
At a recent Kubernetes meetup in Seattle, Kaslin Fields, a Solutions Architect at Oracle Cloud Infrastructure, overviewed functionality to enable persistent storage for containerized apps available through Docker and Kubernetes.
 Kaslin Fields at the Cloud-Native and Kubernetes meetup in Seattle
Kaslin Fields at the Cloud-Native and Kubernetes meetup in SeattleAs mentioned above, the application data maps to the containers that cannot be changed on the fly. This way, one has to separate data from apps. It means that we need to map apps to containers, and app data to somewhere else, which happens to be volumes. Both Docker and Kubernetes have tooling that help to manage volumes, as well as plug-ins that reach out to several types of cloud infrastructure.
“If your containers can never change while they’re running and writing new data inside the running container would be a change, then where’s all your data supposed to go?!
—Kaslin Fields, Oracle
Taking WordPress-based apps as an example, Kaslin explained how Docker volumes and swarms, Kubernetes PersistentVolumes, and Oracle’s Volume Provisioner help to enable persistence.
Docker volumes and swarms
One way to approach the situation is with Docker volumes, which store data, and Swarm, which functions as the Docker’s container orchestrator.
Volumes are considered the preferred way today to ensure data persistence with Docker containers. They should be considered in comparison to the earlier bind mounts method. While bind mounts are heavily dependent on the directory structure of the host machine, volumes are managed by Docker itself—either via CLI commands or API. This way, it is easier to back up or migrate volumes, which can be distributed across multiple containers. It is also possible to store volumes on remote hosts or cloud providers, to encrypt volume contents, or to extend their functionality.
Furthermore, volumes don’t increase the size of containers they are using, and the volume’s contents exist outside the life cycle of a taken container.
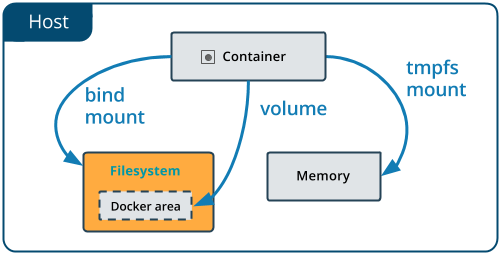 Docker volumes vs. bind mounts (Image credit)
Docker volumes vs. bind mounts (Image credit)A swarm, actually, represents a group of machines running on Docker and joined to a cluster. With swarms, you continue to utilize the familiar Docker commands with the only difference that they are now executed on a cluster by a swarm manager. By switching on the swarm mode, you assign your physical/virtual machine as a swarm manager.
Docker volumes work natively with the swarm mode. Docker itself will seek a volume on every node of a swarm, which means a project might need more than one volume. Alternatively, volumes can be created with multiple nodes.
Developers can use local storage or plug-ins from NetApp and several other storage companies to create a file storage system through an API. Because Docker, and thus the swarm mode, come with only a local driver, the plug-ins make it aware of your swarms and match volumes with service tasks. For instance, there is such a plug-in for Docker volumes on Oracle Cloud Infrastructure (OCI).
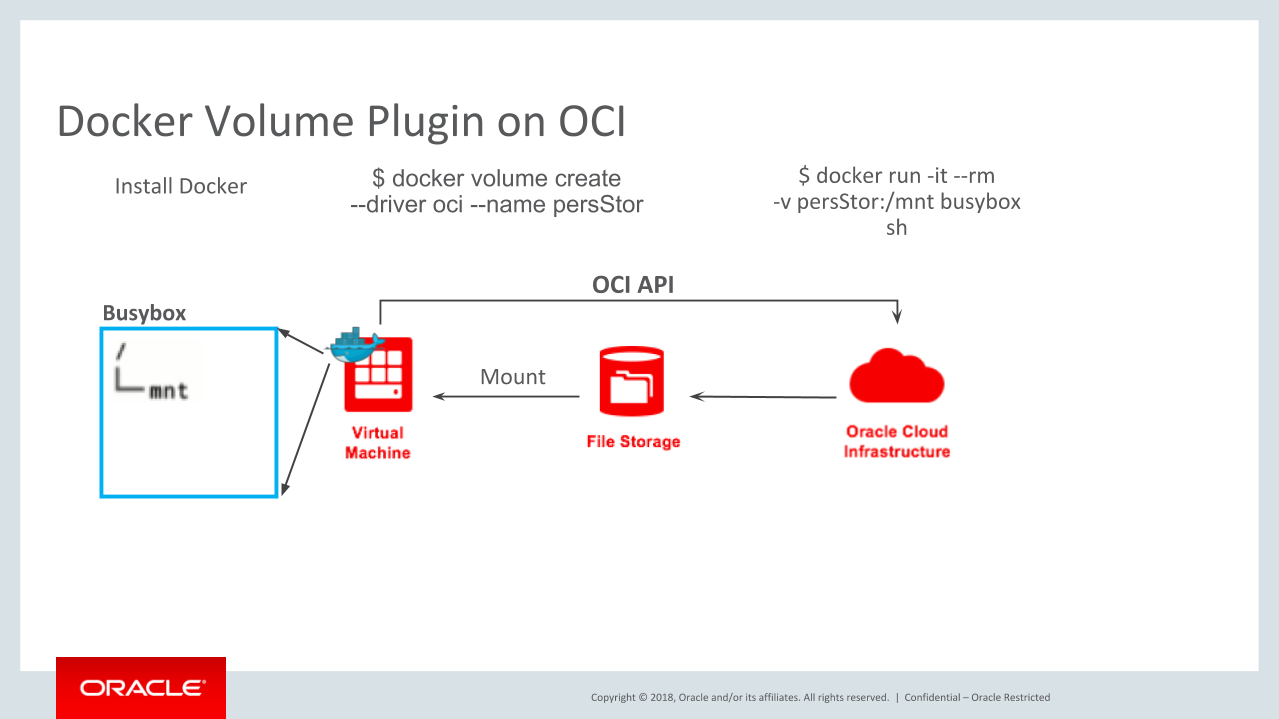 A sample architecture of Docker Volume Plugin on Oracle Cloud Infrastructure (Image credit)
A sample architecture of Docker Volume Plugin on Oracle Cloud Infrastructure (Image credit)
Kubernetes PersistentVolumes
With the continued, growing strength of Kubernetes, it’s no surprise to see a Kube-centric path to persistent storage. The relatively new Kubernetes PersistentVolumes, which date only to September 2017, provide this path.
As with Docker volumes, PersistentVolumes are fully managed by Kubernetes itself. Typically, PersistentVolumes are backed by Compute Engine persistent disks and can be used with other storage types like a network file system. PersistentVolumes can be dynamically provisioned, and the user doesn’t need to manually create or delete the backing storage.
 Kaslin Fields, a Solutions Architect at Oracle
Kaslin Fields, a Solutions Architect at OracleAs PersistentVolumes are independent of Kubernetes pods, the disk and data continue to exist as the cluster changes and if pods are deleted or recreated. It’s important to remember that pods are considered to be “cattle” (rather than “pets”), so they can be terminated or go down if a machine failures. This was an obvious issue with the original Kubernetes volumes. With PersistentVolumes and its PersistentVolumeClaims sibling, physical storage is invoked, so that pods can go down, but the storage persists.
Oracle’s Volume Provisioner
When it comes to Oracle, the company offers its OCI Volume Provisioner. The tool enables dynamic provisioning of storage resources for running Kubernetes on Oracle Cloud Infrastructure. It uses the OCI Flexvolume Driver to bind storage resources to Kubernetes nodes. The volume provisioner offers support for block volumes.
With these blocks, one is able to create, attach, connect, and move volumes as needed to meet storage and app requirements. Once a block volume is attached and connected to an instance, one can use it as a regular hard drive. The great thing is that no loss of data is expected if you disconnect a volumes and reattach it to any other instance.
“In the real world, all of these containers work within availability domains. We especially need persistent storage for highly available apps, so we want persistent block storage and a driver that lets Kubernetes know how to talk to that block storage.” —Kaslin Fields, Oracle
Whichever approach is taken, a project that moves into deployment will need to reach to cloud-computing infrastructure. Cloud providers offer solutions, such as Amazon’s AppStream, Google’s Persistent Disk, and Docker’s Cloudstor for Azure.
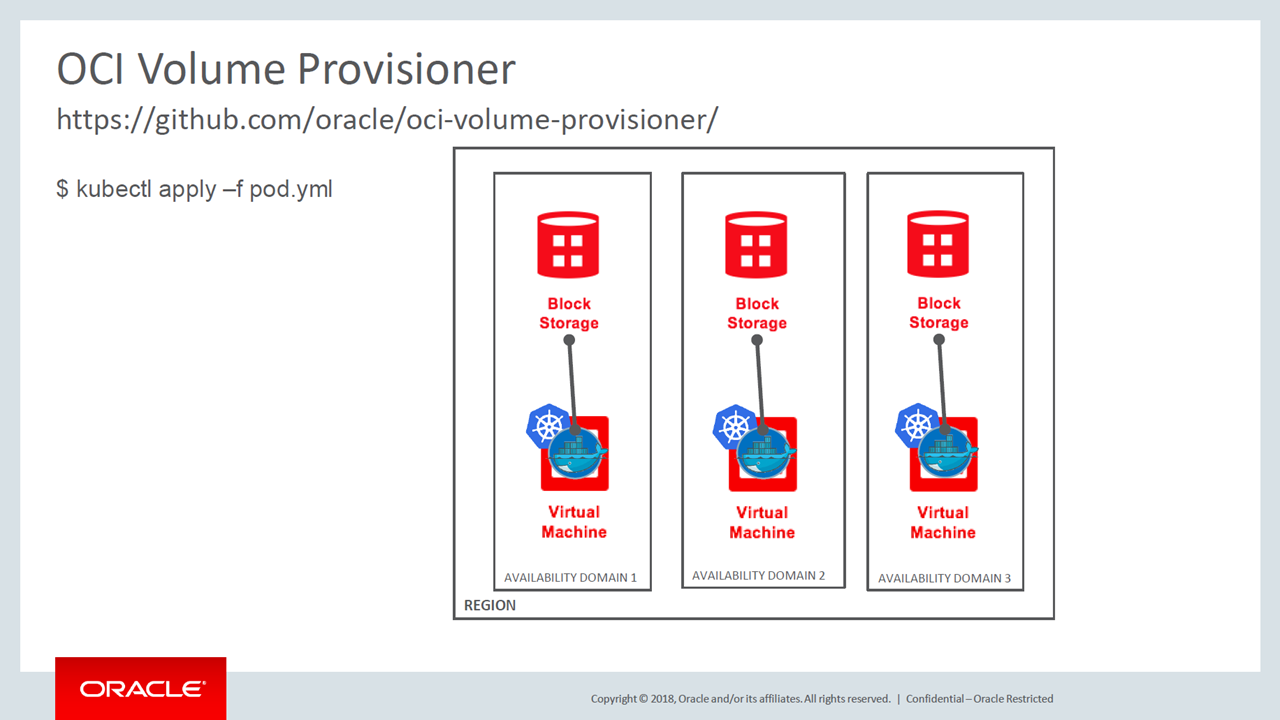 A high-level architecture of the OCI Volume Provisioner (Image credit)
A high-level architecture of the OCI Volume Provisioner (Image credit)The ripples caused by image immutability will roil all enterprises and developers who seek the speed and efficiency of containers, but also have a need for data persistence. No doubt increasing numbers of these enterprises will choose one of the the paths outlined here to solve this problem. It will be instructive to see which of these paths, or perhaps another path, becomes the road most traveled.
Want details? Watch the video!
Table of contents
|
Related slides
Further reading
- Managing Multi-Cluster Workloads with Google Kubernetes Engine
- Deploying Services to Cloud Foundry Using Kubernetes: Less BOSH, More Freedom
- A Multitude of Kubernetes Deployment Tools: Kubespray, kops, and kubeadm
About the expert






