
Enabling High Availability and Disaster Recovery in Kubernetes

Since its initial launch back in 2014, Kubernetes has now grown and evolved to enjoy being the most popular choice when it comes to container orchestration systems, according to the survey by the Cloud Native Computing Foundation. With this steady rise in popularity, many organizations will be interested in adopting the technology. However, they may experience some of the challenges the early adopters of Kubernetes first encountered.
At a recent meetup in Sunnyvale, Rushi Ns, Chief Architect at SAP, provided guidelines for building enterprise-ready Kubernetes cluster, while achieving high availability and disaster recovery across the selected Kubernetes distribution.
 Rushi Ns of SAP at the meetup in Sunnyvale
Rushi Ns of SAP at the meetup in Sunnyvale
A variety of Kubernetes distributions
According to Rushi, there are 30–40 Kubernetes distributions today. When deciding on which one to use, some key questions better be raised to narrow down the available choices. These questions include:
- What do my developers need?
- Do we need multi-cloud?
- Do we need an open-source or an enterprise-grade distribution?
- Do we need fully automated deployment?
- How do we get support?
“As an architect, I should be in a position to think about my distribution, fulfill my developers’ requests, and provide support to my engineering team. When you go into production with Kubernetes, these are the elements you need.” —Rushi Ns, SAP
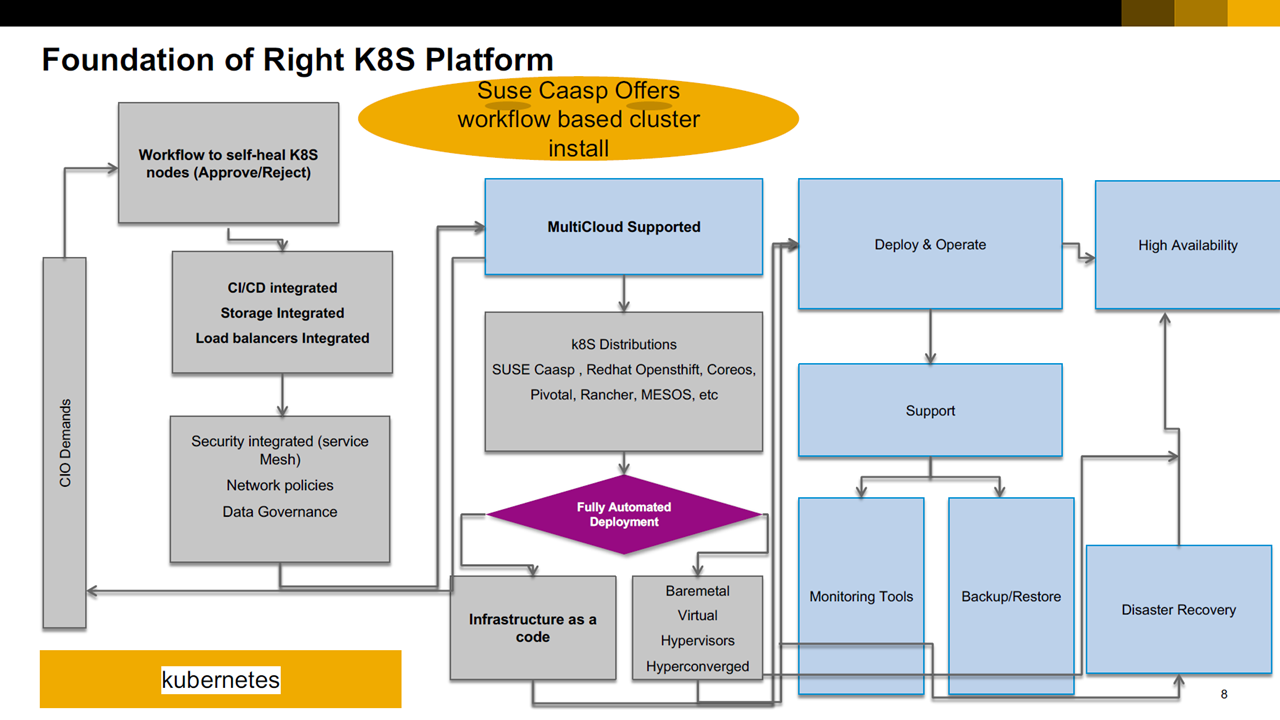 Flowchart for choosing a platform (Image credit)
Flowchart for choosing a platform (Image credit)“You have to choose the right platform based on your organization’s use cases and your engineering team’s development experiences. For production-grade Kubernetes, high availability and disaster recovery should be in place.” —Rushi Ns, SAP
Two approaches to high availability
To enable high availability, Rushi suggested two primary Kubernetes deployment models: multi-cluster and leader election. For a multi-cluster model, the following guidelines may come helpful:
- deploy masters and workers in a secondary data center
- configure the network with LACP
- combine storage virtual machines with Kubernetes Persistent Volumes
- employ active-active load balancing
- use artifactory high availability
“When you deploy Kubernetes multi-cluster, you can install one master on your on-premises cluster and another master anywhere, whether it’s on your data center or in the cloud.”
—Rushi Ns, SAP
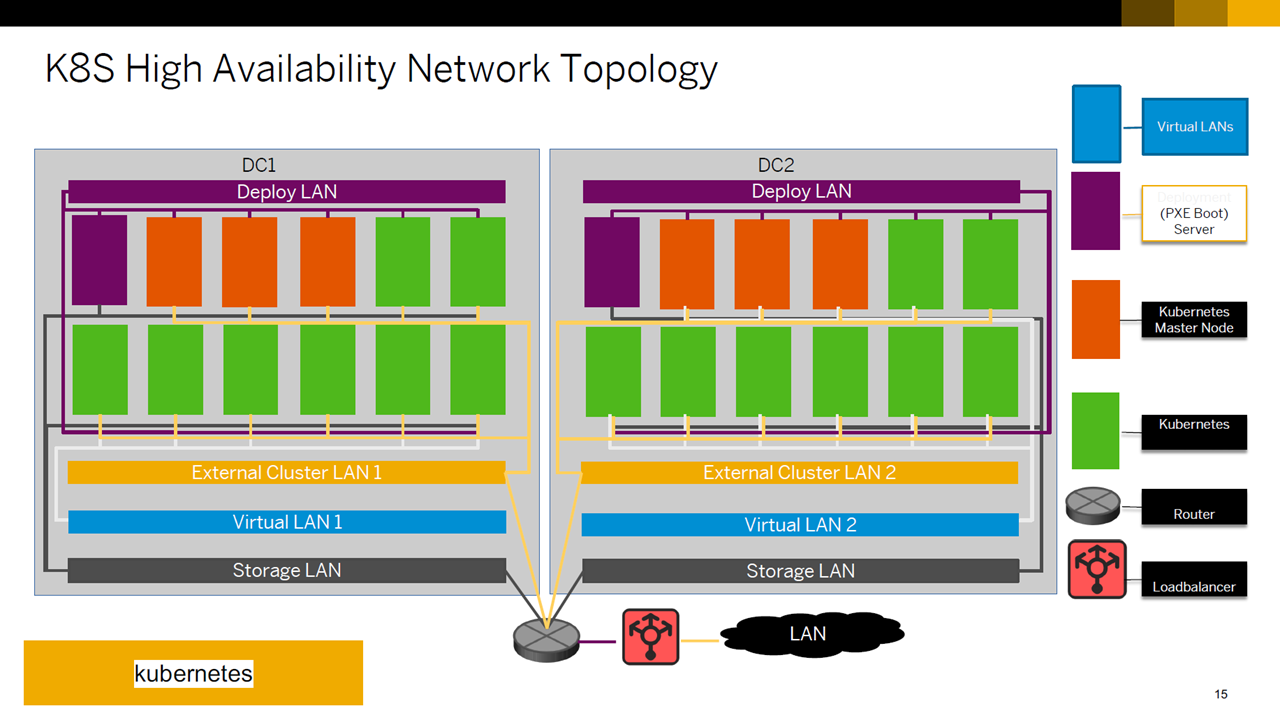 Kubernetes architecture with high availability (Image credit)
Kubernetes architecture with high availability (Image credit)On the other hand, with leader election, one master is replicated to achieve high availability.
“Another approach is by electing a leader. By nature, HAProxy in the Kubernetes API is the only load balancer. When you install three masters, HAProxy talks to each master and distributes the etcd configuration. If I elect one leader, I can replicate the master control plane to multiple data centers.” —Rushi Ns, SAP
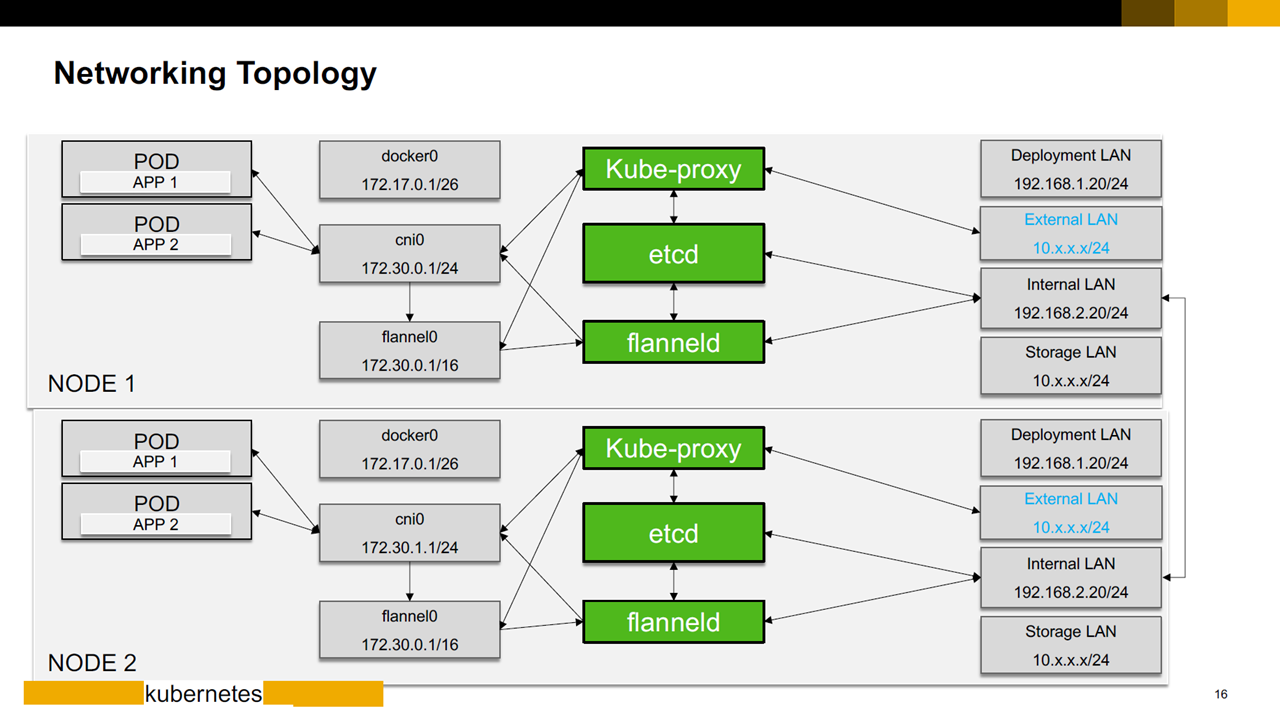 Example dual data center model with high availability (Image credit)
Example dual data center model with high availability (Image credit)For multi-cloud Kubernetes, Gardener, which is an open-source tool for managing clusters on multiple cloud providers, can be used.
“Gardener is another tool that gives you a multi-cloud feature where you can manage your on-premises cluster and cloud cluster within a single control plane.” —Rushi Ns, SAP
Two options for disaster recovery
In terms of enabling disaster recovery, two methods may be employed—federation and etcd. Federation is a feature within Kubernetes which enables resource syncing across clusters.

“You can federate your cluster to tune around on-premises to cloud, so that you can plan your workloads. Federation v2 is very mature today.” —Rushi Ns, SAP
Alternatively, an etcd cluster can be recovered from failure using snapshot and restore. Snapshots can be taken via the command below.
ETCDCTL_API=3 etcdctl --endpoints $ENDPOINT snapshot save snapshot.db
The snapshot can then be employed to initialize a new member of the cluster. The following command will create a new etcd member cluster.
ETCDCTL_API=3 etcdctl snapshot restore snapshot.db \ --name m1 \ --initial-cluster m1=http://host1:2380,m2=http://host2:2380,m3=http://host3:2380 \ --initial-cluster-token etcd-cluster-1 \ --initial-advertise-peer-urls http://host1:2380
Before concluding the session, Rushi shared a few more tips for Kubernetes deployments:
- Practice “infrastructure as code” with fully automated CI/CD pipelines for easier cluster installs and upgrades.
- Prepare network and storage disaster recovery before clusters are installed.
- High availability and disaster recovery should be in place after clusters are installed.
Finally, development teams should always be kept aware of the latest Kubernetes updates and progress.
Want details? Watch the video!
- What are the four pillars of Kubernetes? (00’42”)
- What are the guidelines to choosing a Kubernetes distribution? (4’07”)
- Some guidelines for a software-defined approach? (11’13”)
- Achieving high availability with the dual data center model (15’20”)
- Network topology of clusters with high availability (18’17”)
- Protecting data with disaster recovery solutions (20’00”)
- Questions and answers (24’05”)
Below, you will find the full presentation by Rushi.
Further reading
- NetApp Builds Up a Multi-Cloud Kubernetes-as-a-Service Platform
- Kubernetes Cluster Ops: Options for Configuration Management
- Managing Multi-Cluster Workloads with Google Kubernetes Engine
About the expert






