The Challenges of Data Synchronization

Diverse corporate systems create chaos
Today, the quantity of data we use grows in an explosive manner. We are surrounded by information, we produce it, and we use it. The amount of data that runs across organizations and enterprises is only increasing. At the same time, according to a TDWI report, “data quality quickly degenerates over time…2% of records in a customer file become obsolete in one month.”
So, an organization needs to control and maintain its data enterprise-wide. Surely, the corporate users want their data to be consistent, clean, complete, and synchronized across multiple systems and applications. Therefore, data synchronization should become an important part of organizations’ information systems.
However, the complexity of bidirectional or unidirectional synchronization is very often underestimated, while it may be quite tricky due to a number of factors:
- Different data formats generated by a variety of applications, tools, and databases need to be unified and merged.
- The quality of data synchronized. There is a risk to distribute inconsistent or outdated data enterprise-wide, which may result in additional (and quite notable) data cleansing expenses.
- Finding a common identifier across the systems matching corresponding records is not a trivial task. Most likely, there’s no a single primary key shared across all the systems within an organization. Even if you want to take an e-mail or a phone number as an ID for the purpose, see above. There are myriads of ways to write down a phone number, while e-mail addresses can be misspelled.
- Not to forget ongoing maintenance, meaning that as soon as new data enters an application, the next step is to synchronize it between the other applications and systems.
Keeping the data right, companies may minimize the rework caused by failed transactions or customer service issues, and reduce wasted time and materials in industries such as manufacturing and logistics.
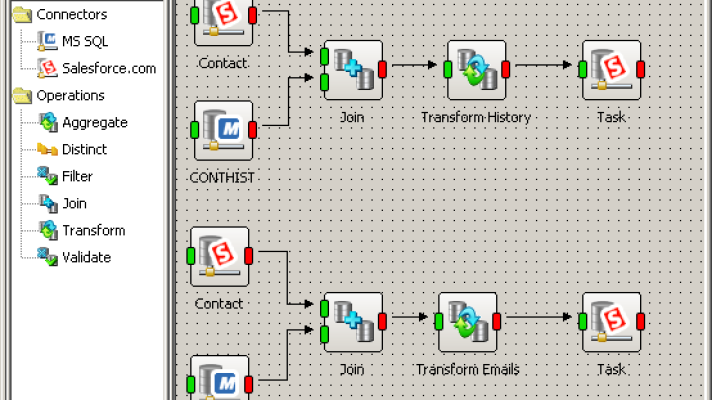
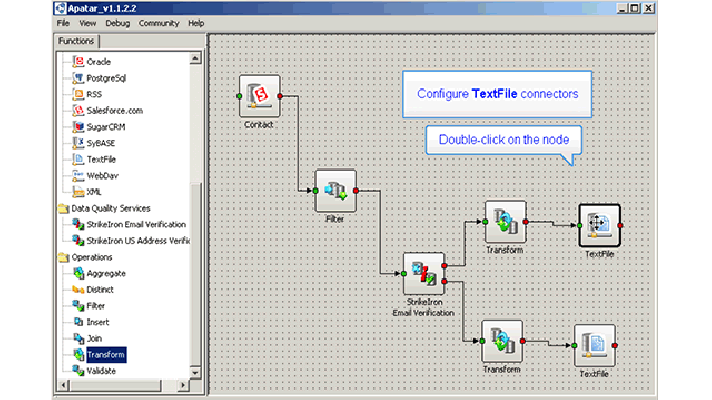
 Customer data synchronization architecture (image credit)
Customer data synchronization architecture (image credit)
How to synchronize?

Alex Berson
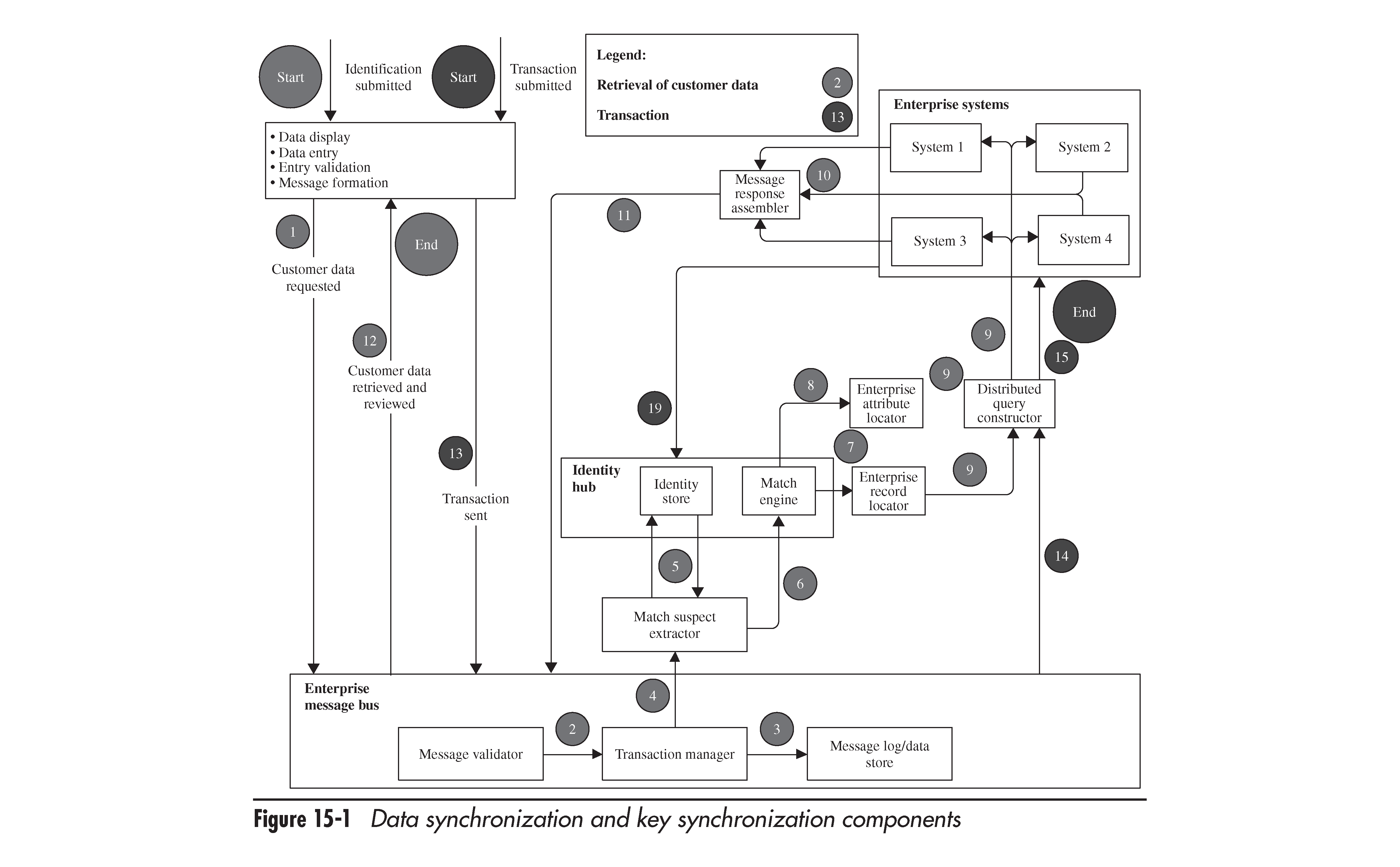
In their book, “Master Data Management and Customer Data Integration for a Global Enterprise,” Alex Berson and Larry Dubov present a vision of a possible data synchronization architecture and workflow. The approach is very comprehensive and worth reading.
In particular, when talking about ETL, the authors suggest having a data acquisition/loading zone, where information from multiple sources can be unified into a common format and transformed. Then, the staging zone could be “a holding area for the already cleansed, enriched, and transformed data received from the loading zone.” Alex and Larry do not insist on having obligatory bidirectional sync, since a number of one-way synchronizations instead could be easier to implement and maintain.
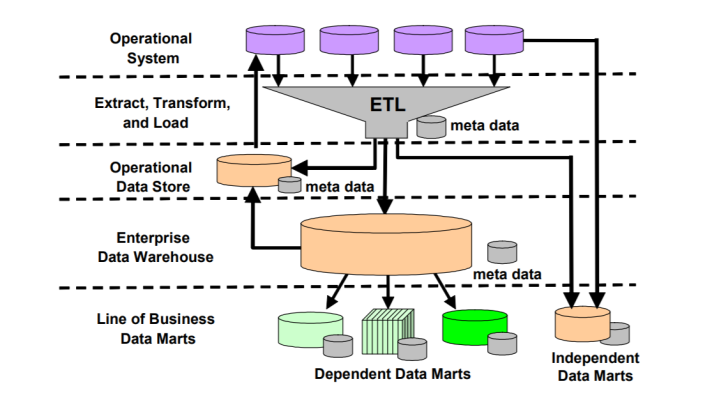
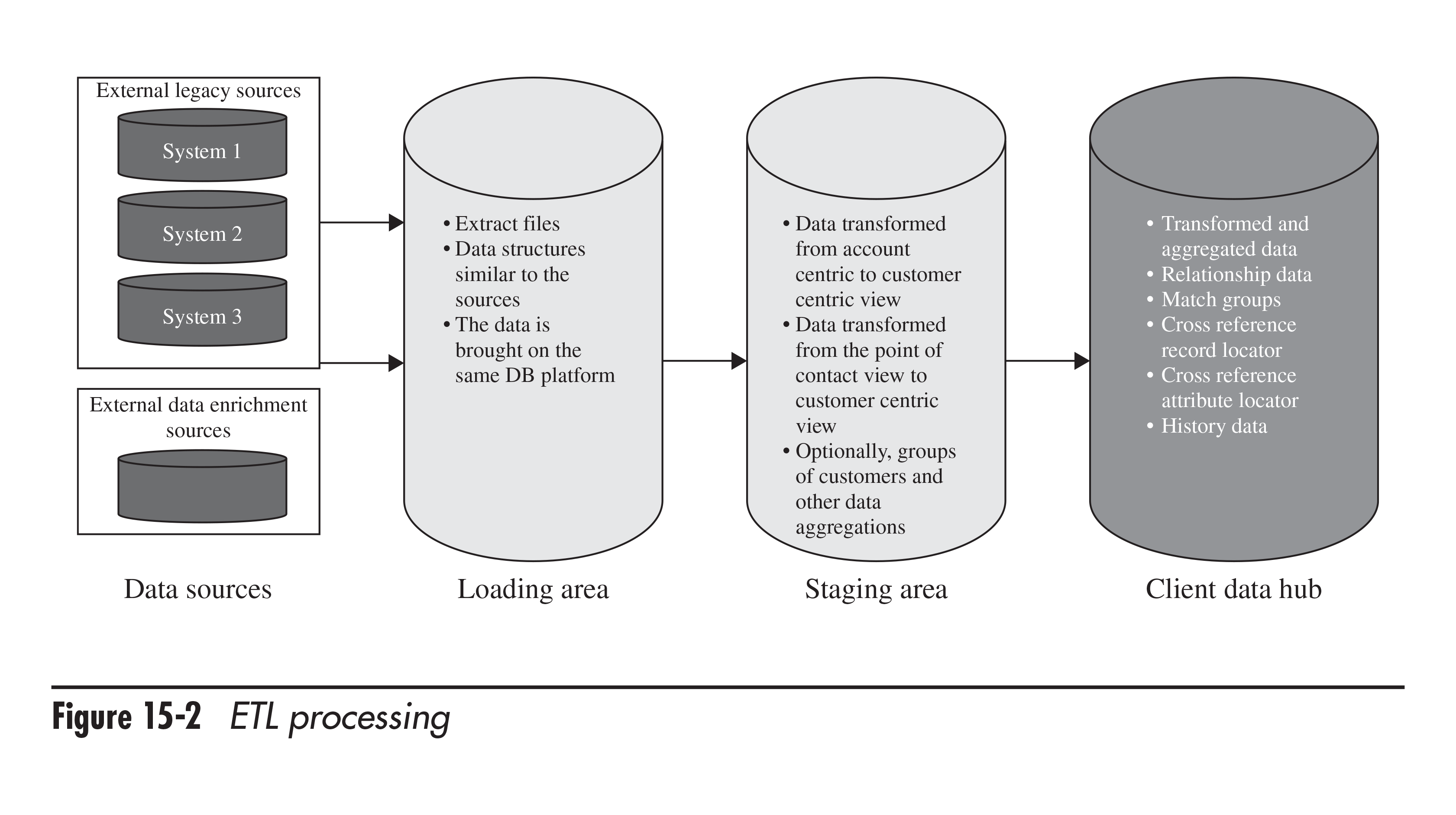 Using a staging area during the ETL process (image credit)
Using a staging area during the ETL process (image credit)One of the important things is having “transactional conflict-resolution mechanisms” to eliminate inconsistencies, as well as implementing business rules for reconciliation of changes. According to the authors, real-time data processing “should take full advantage of service-oriented architecture, including the enterprise service bus zone, and in many cases is implemented as a set of transactional services.” The main transactional environment could maintain data integrity, serving as “the sole source of changes,” propagating them “to all downstream systems that use this data.”

Larry Dubov
In the book, Alex and Larry also explain how to deal with MDM, compliance, security, CDI, data validation, testing, metadata, etc.
It’s next to impossible to present all the ideas in a single post, so check out chapter 6 and and chapter 11 of the book (reprinted by TechTarget), as well as read a supplementary article at SearchDataManagement.com. You may also find it useful to learn about the issues when synchronizing data in Salesforce CRM and QuickBooks from our related blog post.
Further reading
- Building a Bridge Between Salesforce CRM and QuickBooks
- Implementing a Business Rules–Based Approach to Data Quality
- The Three Most Common Problems Faced During Data Migration