
Building a Keras-Based Image Classifier Using TensorFlow for a Back End

Keras + TensorFlow
![]()
Written in Python, Keras is a high-level neural networks API that can be run on top of TensorFlow. This API was designed to provide machine learning enthusiasts with a tool that enables easy and fast prototyping, supports both convolutional and recurrent neural networks (and a combination of the two), while running on a CPU or GPU.
At the recent webinar, the attendees learned how to build an image classifier from scratch using Keras on top of TensorFlow, how containerization can help, how to fight data overfitting and reach 90% of accuracy, etc.
Rajiv Shah, a senior data scientist at Catepillar Inc., demonstrated how to build a Keras-based image classifier with TensorFlow as a back end.
The webinar highlighted how to:
- run a Docker container on Keras
- train a simple convolutional network (as a baseline)
- use the bottleneck features of a pre-trained network
- fine-tune the top layers of a pre-trained network
Building an image classifier, Rajiv actively employed such Keras functionality as fit_generator to train a model and ImageDataGenerator for real-time data augmentation.
Running a Docker container
With numerous Python libraries that have conflicting dependencies, it is quite difficult to replicate the work done. Containerization helps to isolate workers from the environment and abstract away some version dependencies that may be different for different jobs.
In his example, Rajiv uses a Docker container—ermaker/keras-jupyter. Those, who want to run his particular code, can do it with the following command:
docker run -d -p 8888:8888 -e KERAS_BACKEND=tensorflow -v /Users/rajivshah/Code:/notebook ermaker/keras-jupyter
Then, you have to substitute a local path to the Rajiv’s tutorial and data for /Users/rajivshah/Code.
The exemplified data set
As a sample image classifier was to differentiate cats and dogs, two major sources of data were chosen:
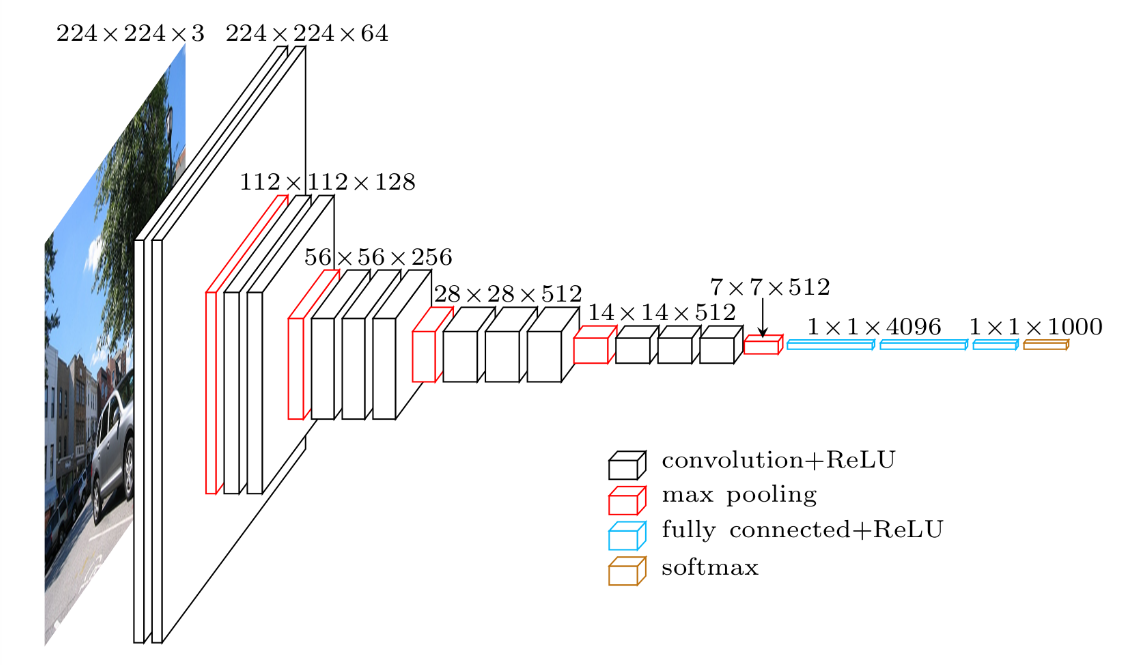 The VGG16 model architecture (Image credit)
The VGG16 model architecture (Image credit)(Note: for his example, Rajiv utilized only 2×1,000 training images and 2×400 testing images among the 2×12,500 available to demonstrate how to train a small data set.)
Neural networks are prone to data overfitting, when some random error or noise occurs instead of the underlying relationship. To enhance a data set, random transformation is applied to reduce overfitting and enable better generalization for a convolutional network. With data augmentation, Rajiv achieved ~80% of accuracy on the validation data set.
As a result of training the data set using the VGG16 model with a small multi-layer perceptron, Rajiv was able to identify bottleneck features. Then, he evaluated the bottleneck model and reached 90% of accuracy on the validation in just a minute (~20 epochs), employing only 8% of the samples available on the Kaggle data set.
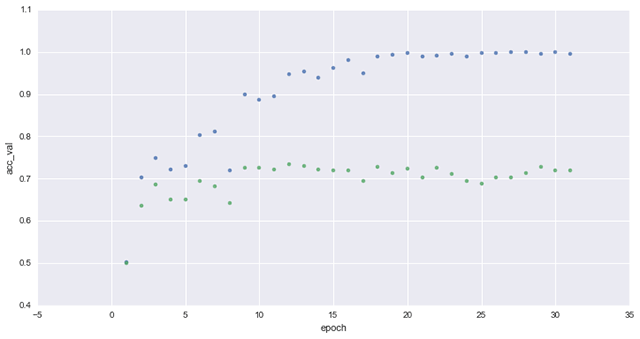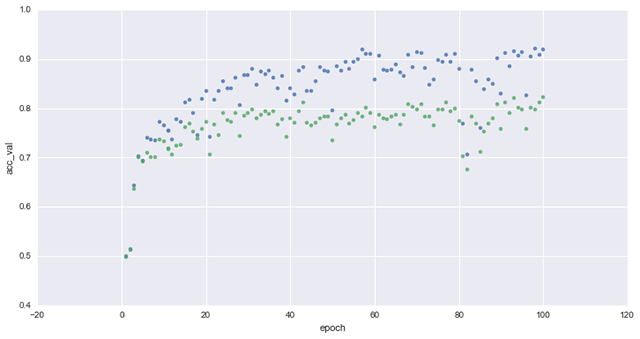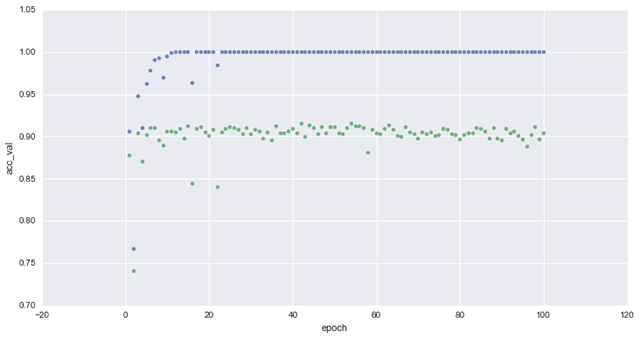
In his research, Rajiv relied on this Keras tutorial and this workshop. You can find the source code for each of the steps he took on Rajiv’s GitHub repo. His presentation is also available here.
Want detail? Watch the webinar recording!
Further reading
- Building a Chatbot with TensorFlow and Keras
- Using Convolutional Neural Networks and TensorFlow for Image Classification
- Image and Text Recognition with TensorFlow Using Convolutional Neural Networks
- Using Recurrent Neural Networks and TensorFlow to Recognize Handwriting
About the expert

Rajiv Shah is a Senior Data Scientist at Caterpillar Inc. and an Adjunct Assistant Professor at the University of Illinois at Chicago. He is an active member of the data science community in Chicago with an interest into public policy issues, such as surveillance in Chicago. Rajiv has a PhD from the University of Illinois at Urbana Champaign.

