Ins and Outs of Integrating TensorFlow with Existing Infrastructure

At TensorFlow Dev Summit 2017, Jonathan Hseu of the Google Brain team elaborated on how to integrate TensorFlow with your infrastructure. The three major steps to take can be broadly divided into three high-level perspectives: data preparation, training, and serving in production.
With all of the three steps outlined, this blog post highlights nuances to consider: the perks of distributed training, how containers help out, why input / output file formats matter, etc.
Stage #1: Preparing data
According to Jonathan, the initial step invokes:
- import from various resources (Hive, MySQL, etc.)
- pre-processing (e.g., compute aggregates or do joins)
- export in a file supported by TensorFlow
To do these kind of things, engineers mostly use such tools as Apache Spark, Hadoop MapReduce, or Apache Beam.
Jonathan exemplified feeding in user data stored in, say, Hive—web impressions or clicks—to compute aggregates or join data (for example, user data per region). One may also need to make vocabulary generation in case one uses word embeddings.

Vocabulary generation means mapping from words to IDs, and the IDs map to the embedding layer. Then follows the test split and the output is exported in a file format that TensorFlow understands. Actually, the file format you are using within your input pipeline affects the speed and quality of model training. So, Jonathan enumerated those ones to employ:
tf.Example,tf.SequenceExample(especially for training recurrent neural networks), andtf.Records(which is TensorFlow-specific)- Native TensorFlow ops to read JSON and CSV
One may also feed data directly from Python, which is slower than the two formats above, but allows for experimenting easily and is very useful when it comes to reinforcement learning.
To enable TensorFlow integration with other open-source frameworks, Johathan highly recommended using TFRecords support, which is native for Apache Beam. For Hadoop MapReduce or Apache Spark, one can check out these templates.
Stage #2: Training data
Models may be trained either:
- locally—on your machine or a VM—a common case for small data sets or debugging,
- or in a distributed environment, which is faster, but still requires appropriate infrastructure.
In a distributed model, there are two types of jobs—parameter servers and workers. The recommended setup is between graph replication, where workers operate independently with no need to communicate with each other, but with the parameter servers only.
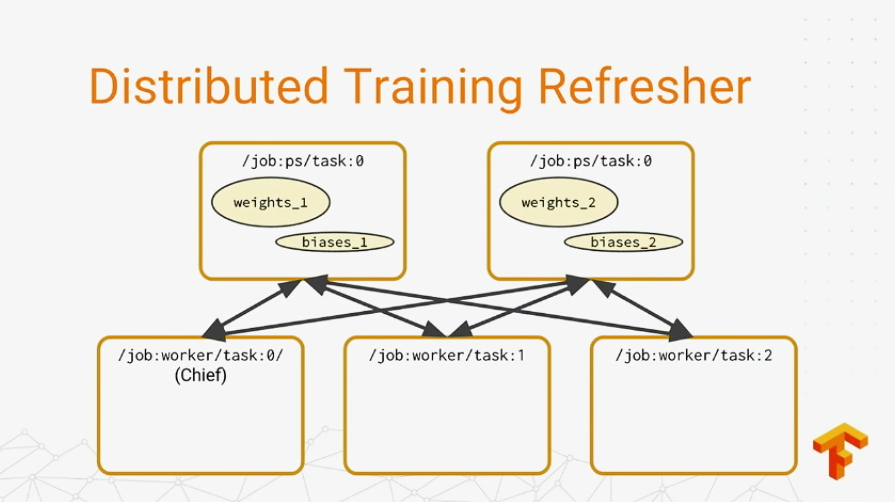
“So, the reason you would want to run a distributed storage is for your input data, so each worker can read from a single source, and for checkpoints in the exported model itself.”
—Jonathan Hseu, Google Brain
Two things are essential for running a distributed training: cluster management and distributed storage. Jonathan recommended such cluster managers as Apache Mesos, Kubernetes, Hadoop YARN, and Slurm. As distributed storage solutions, one may consider using HDFS, Google Cloud Storage, or AWS.
Though using some container engine (Docker or rkt) is optional, there are grounds for doing so. Containers isolate workers from the environment, which is useful as some jobs may have some version dependencies that differ from the other jobs.

“A specific example here is that eventually we’ll release TensorFlow 2.0. TensorFlow uses semantic versioning, and at 2.0 we may make some backwards incompatible changes. And suppose you want to upgrade to TensorFlow 2.0 in your organization. Then, the containers make it much easier to enable gradual updates because you don’t have to upgrade every job at once. You can pin jobs to a particular TensorFlow version and update one by one.”
—Jonathan Hseu, Google Brain
Jonathan demonstrated what the code for the distributed model looks like.

Stage #3: Serving in production
The configuration to set up depends on an underlying infrastructure. You can find the common templates or check out open-sourced code to run on Spark at the TensorFlowOnSpark repository.
As with the input file formats, there are some preferences for the exported model:
SavedModel(recommended), a standard format for TensorFlow models that already includes such required assets as vocabularies.GraphDef, a frozen graph for particular uses—for example, mobile.

To serve the model in production, one can choose from the following options:
- TensorFlow Serving
- In-process TensorFlow (a standard mode, mostly for specific usage like mobile)
- A hosted service
No surprise that the first option on the list is the one to fit better as TensorFlow Serving loads a new version of a model, batches inputs for efficiency, ensures isolation between multiple models, and handles a lot more nuances.
Finally, Jonathan suggested to have a look at the shared libraries for constructing and executing TensorFlow graphs in Go and in Java.
Want details? Watch the video!
Further reading
- Using Multi-Threading to Build Neural Networks with TensorFlow and Apache Spark
- Performance of Distributed TensorFlow: A Multi-Node and Multi-GPU Configuration
- Building a Keras-Based Image Classifier Using TensorFlow for a Back End
- TensorFlow in the Cloud: Accelerating Resources with Elastic GPUs
About the expert
Jonathan Hseu is a software engineer working on TensorFlow with the Google Brain team. His primary interests are machine learning and distributed systems. Previously, Jonathan worked as tech lead of data infrastructure at Dropbox and tech lead/manager of logs analysis infrastructure at Google. You can check out his GitHub profile.